#调用sklearn库进行LDA分析
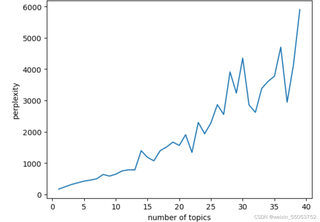
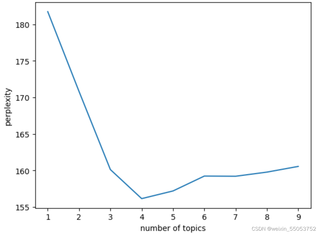
使用python中的sklearn进行LDA主题分析,最后的困惑度曲线一直在上升,当n_max_topics = 10时,会出现一个拐点,拐点处的主题数量与研究输入的主题类型一致,输出的关键词也能较为清晰地分辨主题,但当n_max_topics = 40或者更高时,困惑度曲线呈现上升的情况,这种情况是否是正常的呢?如图,困惑度旁边的数值大小代表什么呢?有些文章中的数值在1000以上,而我的在100左右,这种情况要如何分析呢?

#调用sklearn库进行LDA分析
使用python中的sklearn进行LDA主题分析,最后的困惑度曲线一直在上升,当n_max_topics = 10时,会出现一个拐点,拐点处的主题数量与研究输入的主题类型一致,输出的关键词也能较为清晰地分辨主题,但当n_max_topics = 40或者更高时,困惑度曲线呈现上升的情况,这种情况是否是正常的呢?如图,困惑度旁边的数值大小代表什么呢?有些文章中的数值在1000以上,而我的在100左右,这种情况要如何分析呢?
 分享
分享
以下回复参考:皆我百晓生、券券喵儿等免费微信小程序作答:
看起来你正在使用sklearn进行LDA(潜在狄利克雷分配)主题分析,并遇到了困惑度(perplexity)曲线的问题。困惑度是一个用于评估LDA模型质量的指标,其值越低表示模型质量越好。通常,随着主题数量的增加,困惑度会先降低然后增加。因此,当你看到困惑度曲线在某个主题数量处达到拐点时,这是很正常的现象。拐点的位置可能与研究内容的主题类型数量有关,但并不一定完全对应。至于困惑度的数值大小,它取决于你的数据集和模型的复杂性等因素,因此不同文章中的数值大小可能会有很大差异。你的困惑度在100左右是一个相对较好的结果,因为较低的困惑度通常表示模型质量更高。对于困惑度曲线的解读如下:随着主题数量的增加,当达到最佳的主题数量时,困惑度达到最低点;超过这个数量后,由于模型开始过度拟合数据,困惑度会开始上升。至于你提到的图3和图4,由于无法看到具体的数值和曲线走向,我只能给出一些大致的建议。如果这些图的困惑度曲线在某一主题数量处达到拐点或最低点,那么这可能是最佳的主题数量。同时需要注意比较不同主题数量下的关键词分布和主题清晰度,以选择最合适的主题数量。如果困惑度曲线持续上升或没有明确的拐点,可能需要考虑数据预处理、特征选择等方面的问题。另外,你也可以尝试使用其他评估指标(如主题一致性得分等)来评估模型质量。总的来说,对于困惑度曲线的解读需要结合实际情况进行分析。如果困惑度曲线在某个主题数量处达到拐点并且输出的关键词能够清晰地分辨主题,那么这可能是最佳的模型配置。否则,可能需要进一步调整模型参数或数据预处理步骤以优化结果。
分享 系统已结题
12月29日
系统已结题
12月29日 已采纳回答
12月21日
创建了问题
12月11日
已采纳回答
12月21日
创建了问题
12月11日


