
ppocr在运行训练检测模型时出现了问题,环境为docker环境
命令:python3 tools/train.py -c configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_cml.yml -o Global.save_model_dir=./output/ Global.pretrained_model=./pre_train/ch_PP-OCRv4_det_train/best_accuracy
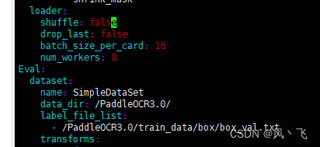
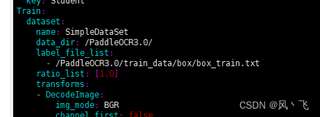
以下为配置文件


 分享
分享
以下回复参考:皆我百晓生、券券喵儿等免费微信小程序作答:
从你给出的错误信息来看,这个问题似乎是由于内存不足引起的。特别是提示信息提到了 "insufficient shared memory",这可能意味着你的系统共享内存(shm)空间不足。
以下是几个可能的解决方案:
/dev/shm的大小。你可以通过运行以下命令来查看当前的大小:df -h /dev/shm
如果空间不足,你可以尝试增加它的大小。具体的步骤取决于你的操作系统和Docker配置。你可能需要编辑Docker的配置文件并重新启动Docker服务。注意,这需要管理员权限。
batch size per card设置为16,你可以尝试减小这个值,以减少内存使用。例如,你可以尝试设置为8或4。num workers设置为8,这表示数据加载器有8个工作进程。过多的工作进程可能会消耗大量内存。你可以尝试减少这个值,例如设置为4或2。如果这些更改无法解决你的问题,我建议你查看更详细的日志信息以获取更多线索。尝试找到错误发生在代码的具体位置,这可能有助于确定问题的根源。此外,确保你的Docker容器和PaddleOCR版本都是最新的,以避免由于软件版本不匹配而导致的问题。
分享 创建了问题
1月16日
创建了问题
1月16日

