
#1、问题描述:
编写VAE-TCN代码进行多分类异常检测,结果报错,无法打印图形。
数据集标签分布如下图:

报错如下图:
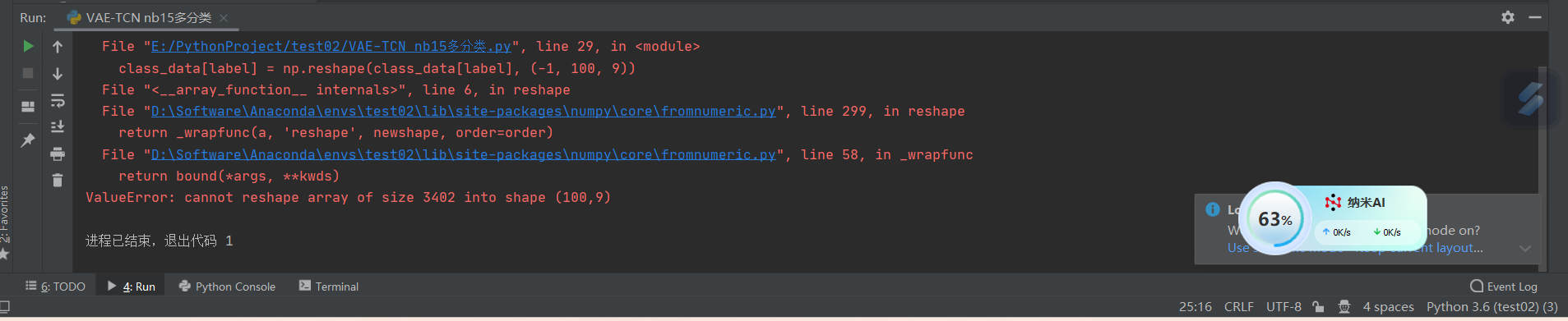
Traceback (most recent call last):
File "E:/PythonProject/test02/VAE-TCN nb15多分类.py", line 29, in <module>
class_data[label] = np.reshape(class_data[label], (-1, 100, 9))
File "<__array_function__ internals>", line 6, in reshape
File "D:\Software\Anaconda\envs\test02\lib\site-packages\numpy\core\fromnumeric.py", line 299, in reshape
return _wrapfunc(a, 'reshape', newshape, order=order)
File "D:\Software\Anaconda\envs\test02\lib\site-packages\numpy\core\fromnumeric.py", line 58, in _wrapfunc
return bound(*args, **kwds)
ValueError: cannot reshape array of size 3402 into shape (100,9)
#2、代码片段
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda, Conv1D, Flatten, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import pandas as pd
import time
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据
csv_path_train = 'E:/dataset/NB-15/reduced_benign.csv'
X_train = pd.read_csv(csv_path_train).values
X_train = np.nan_to_num(MinMaxScaler().fit_transform(StandardScaler().fit_transform(X_train)))
X_train = np.reshape(X_train, (-1, 100, 9))
csv_path_test = 'E:/dataset/NB-15/reduced_ceshi_multiclass.csv'
Y_test = pd.read_csv(csv_path_test)
# 获取所有类别标签
unique_labels = Y_test['label'].unique()
class_data = {}
for label in unique_labels:
class_data[label] = Y_test[Y_test['label'] == label].drop(labels='label', axis=1).values
class_data[label] = np.nan_to_num(MinMaxScaler().fit_transform(StandardScaler().fit_transform(class_data[label])))
class_data[label] = np.reshape(class_data[label], (-1, 100, 9))
original_dim = 9 # 特征维度
latent_dim = 2 # 潜在空间维度
intermediate_dim = 256
batch_size = 100
# 采样函数
def sampling(args):
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
# 编码器
inputs = Input(shape=(100, original_dim))
x = Conv1D(64, kernel_size=3, activation='relu', padding='same')(inputs)
x = Flatten()(x)
z_mean = Dense(latent_dim)(x)
z_log_var = Dense(latent_dim)(x)
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
# 解码器
latent_inputs = Input(shape=(latent_dim,))
x = Dense(100 * 64, activation='relu')(latent_inputs)
x = Reshape((100, 64))(x)
x = Conv1D(64, kernel_size=3, activation='relu', padding='same')(x)
outputs = Conv1D(original_dim, kernel_size=3, activation='sigmoid', padding='same')(x)
decoder = Model(latent_inputs, outputs, name='decoder')
# VAE模型
vae_outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, vae_outputs, name='vae')
# 定义损失函数
def vae_loss(x, x_decoded):
x = K.flatten(x)
x_decoded = K.flatten(x_decoded)
reconstruction_loss = tf.keras.losses.binary_crossentropy(x, x_decoded)
reconstruction_loss *= original_dim * 100
kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var)
kl_loss = K.sum(kl_loss, axis=-1) * -0.5
return K.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss(inputs, vae_outputs))
vae.compile(optimizer='adam')
# 训练VAE
startTime = time.time()
vae.fit(X_train, epochs=100, batch_size=batch_size, validation_data=(list(class_data.values())[0], None))
endTime = time.time()
print(f"Took {round((endTime - startTime), 5)} seconds to calculate.")
vae.summary()
# 预测部分
def evaluate_vae(X_test, model):
reconstructions = model.predict(X_test)
reconstruction_errors = np.mean(np.abs(X_test - reconstructions), axis=(1, 2, 3))
return reconstruction_errors
# 计算每个类别的重构误差
class_errors = {}
for label in unique_labels:
class_errors[label] = evaluate_vae(class_data[label], vae)
# 合并所有重构误差和标签
all_errors = []
all_labels = []
for i, label in enumerate(unique_labels):
all_errors.extend(class_errors[label])
all_labels.extend([i] * len(class_errors[label]))
all_errors = np.array(all_errors)
all_labels = np.array(all_labels)
# 多分类混淆矩阵
predictions = []
thresholds = np.percentile(all_errors, 75) # 使用75%分位数作为阈值
for error in all_errors:
predicted_class = np.argmin(np.abs(thresholds - error))
predictions.append(predicted_class)
predictions = np.array(predictions)
cm = confusion_matrix(all_labels, predictions)
# 计算评价指标
accuracy = np.trace(cm) / np.sum(cm)
precision = []
recall = []
f1 = []
for i in range(len(unique_labels)):
tp = cm[i, i]
fp = np.sum(cm[:, i]) - tp
fn = np.sum(cm[i, :]) - tp
precision.append(tp / (tp + fp) if tp + fp != 0 else 0)
recall.append(tp / (tp + fn) if tp + fn != 0 else 0)
f1.append(2 * (precision[i] * recall[i]) / (precision[i] + recall[i]) if precision[i] + recall[i] != 0 else 0)
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=unique_labels, yticklabels=unique_labels)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
#3、预期效果:
打印出如下三分类和多分类的图形。
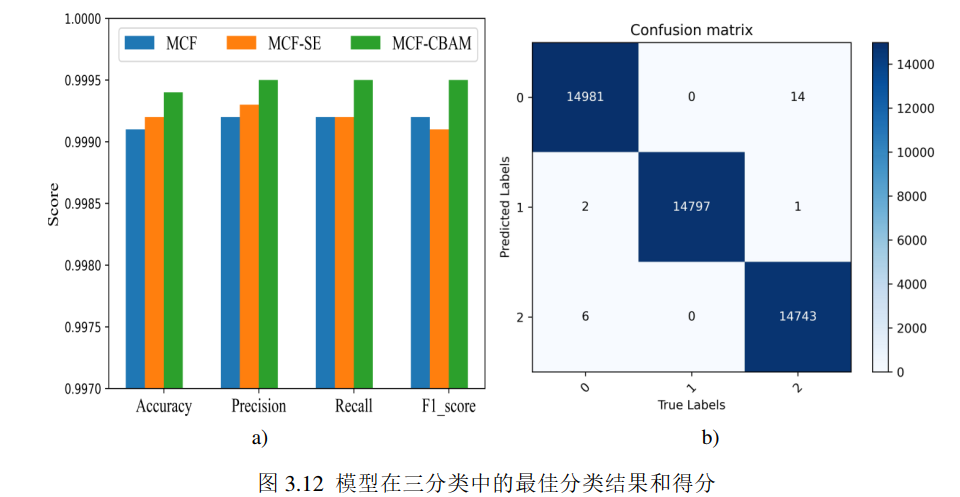
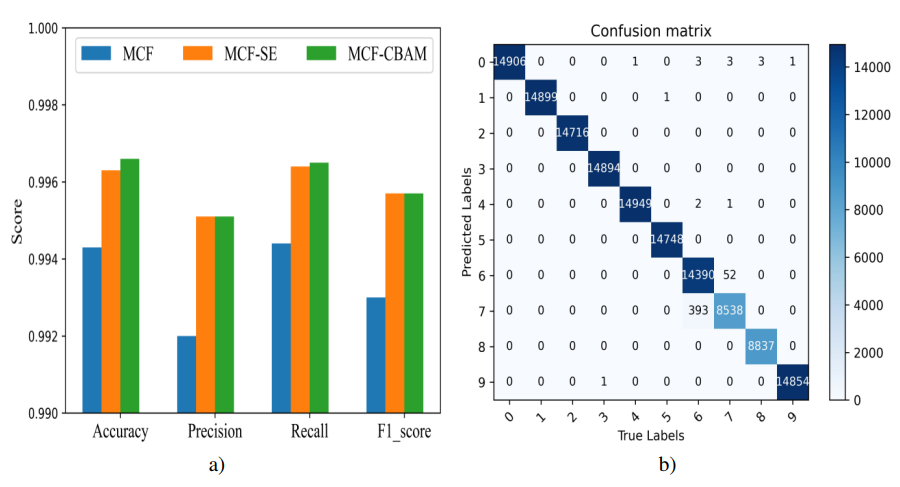
#4、实验环境:服务器为1个256 GB内存的服务器,GPU为Intel(R) Iris(R) Xe Graphics, CPU信息为11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz 2.42 GHz,实验中的所有模型都使用Tensorflow实现。






