
1.用电数据中有部分house数据缺失(NaN格式),请用合适的方法将数据补齐。
2.数据可视化--将数据以合适的形式进行可视化展示。
3.数 据异常值检测-选择合适的算法进行异常值检测,检查原始数据是否有异常值。
4.采用聚类算法(算法自选,但要有自己的改进之处)分.析用户用电行为,并对聚类结果做出合理解 释。
5.查询“电力用户画像” 相关文献,尝试对house进画像。
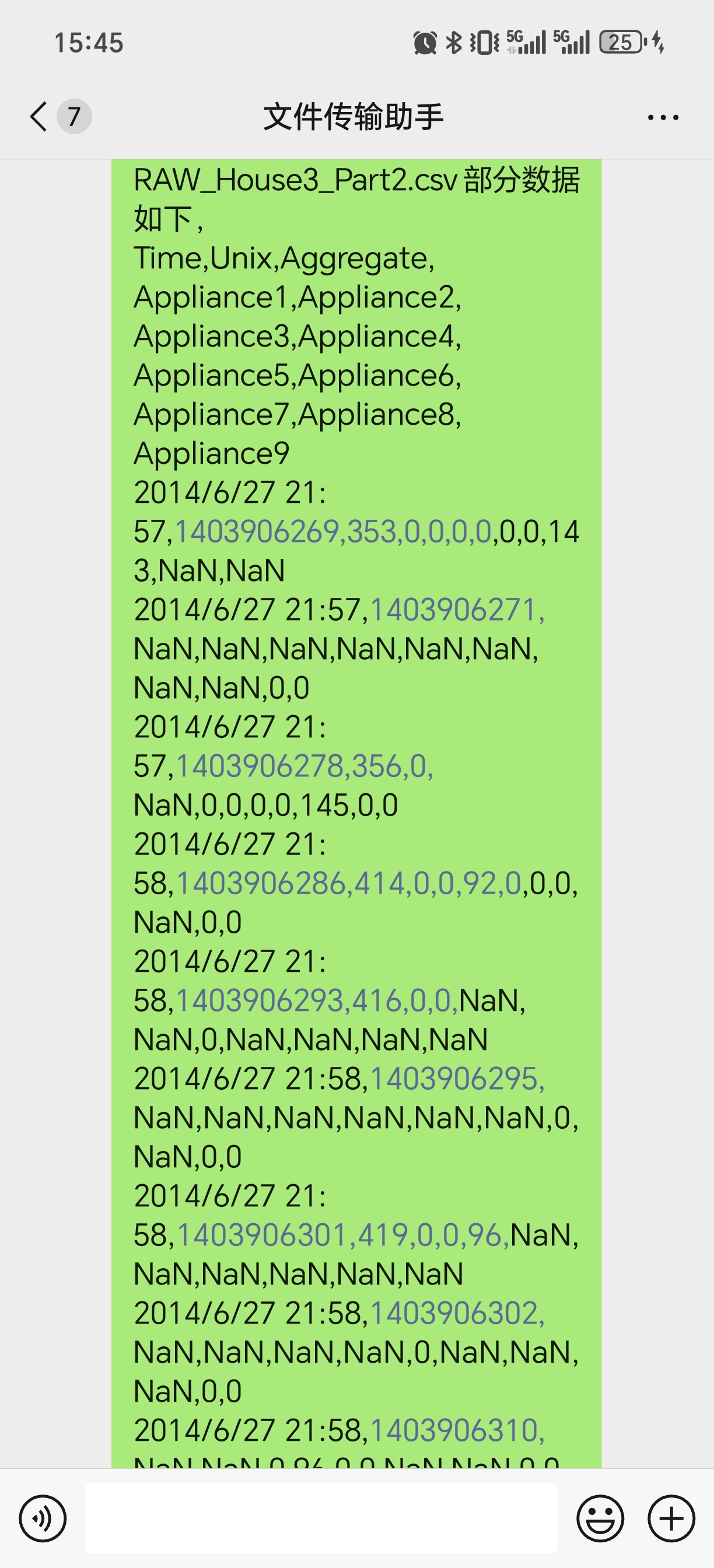
数据缺少的数据集为House 3 House5,(共有House1—13,15—20)
House3数据列名解释如下:
0.Aggregate, 1.Toaster 2.Fridge-Freezer, 3.Freezer, 4.Tumble Dryer,
5.Dishwasher, 6.Washin g Machine, 7.Television Site, 8.Microwave, 9.Kettle
House 5 数据列名解释如下:
0.Aggregate, 1.Fridge-Freezer, 2.Tumble Dryer 3. Washing Machine, 4.Dishwa sher,
5.Desktop Computer, 6. Television Site, 7.Microwave, 8.Kettle, 9.Toaster
House3数据如图







