我想建立不同监管力度下企业行为的演变,但是好像变量里面出了一些问题导致我最后的预测准确度为百分之百了。
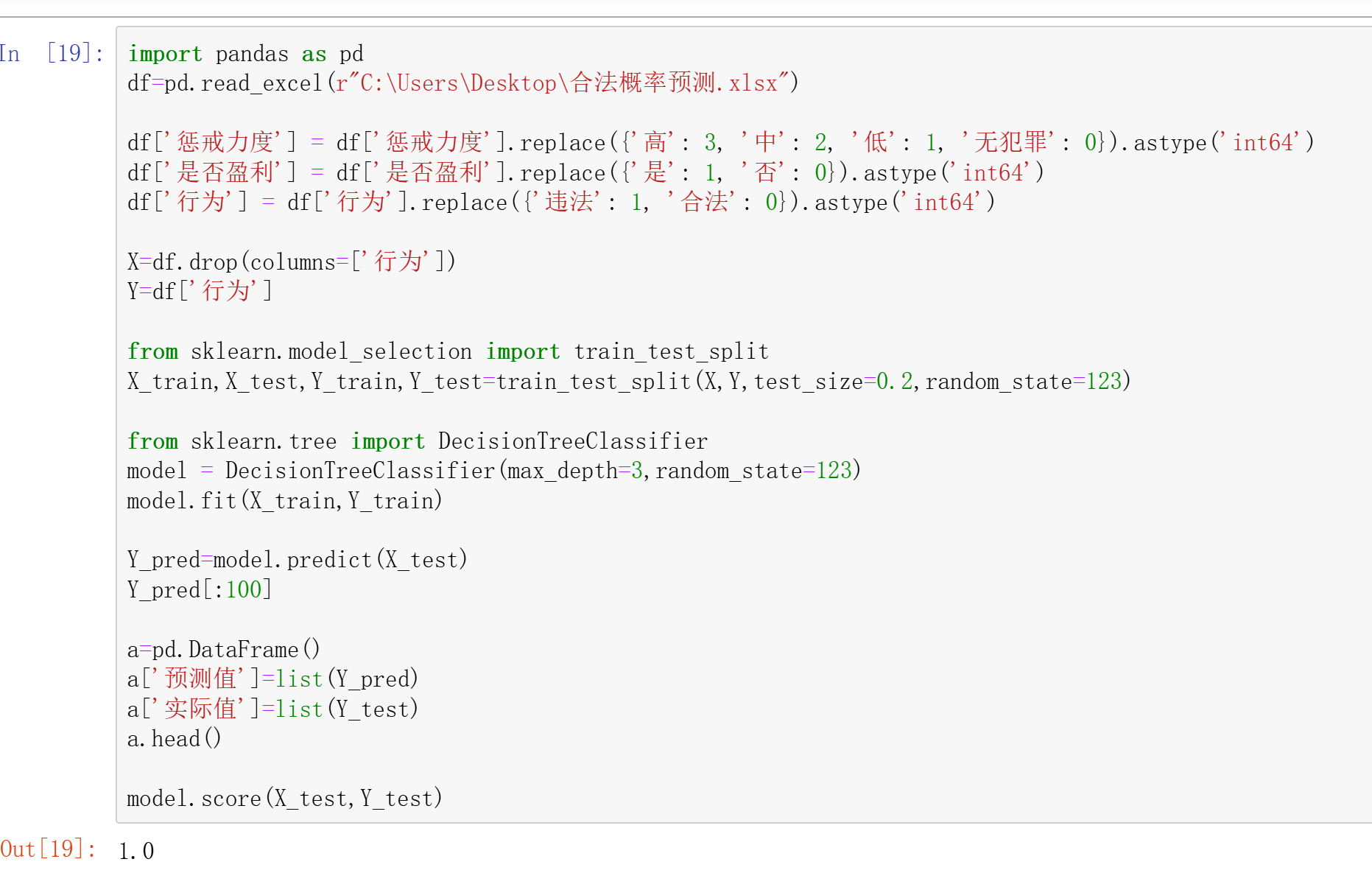
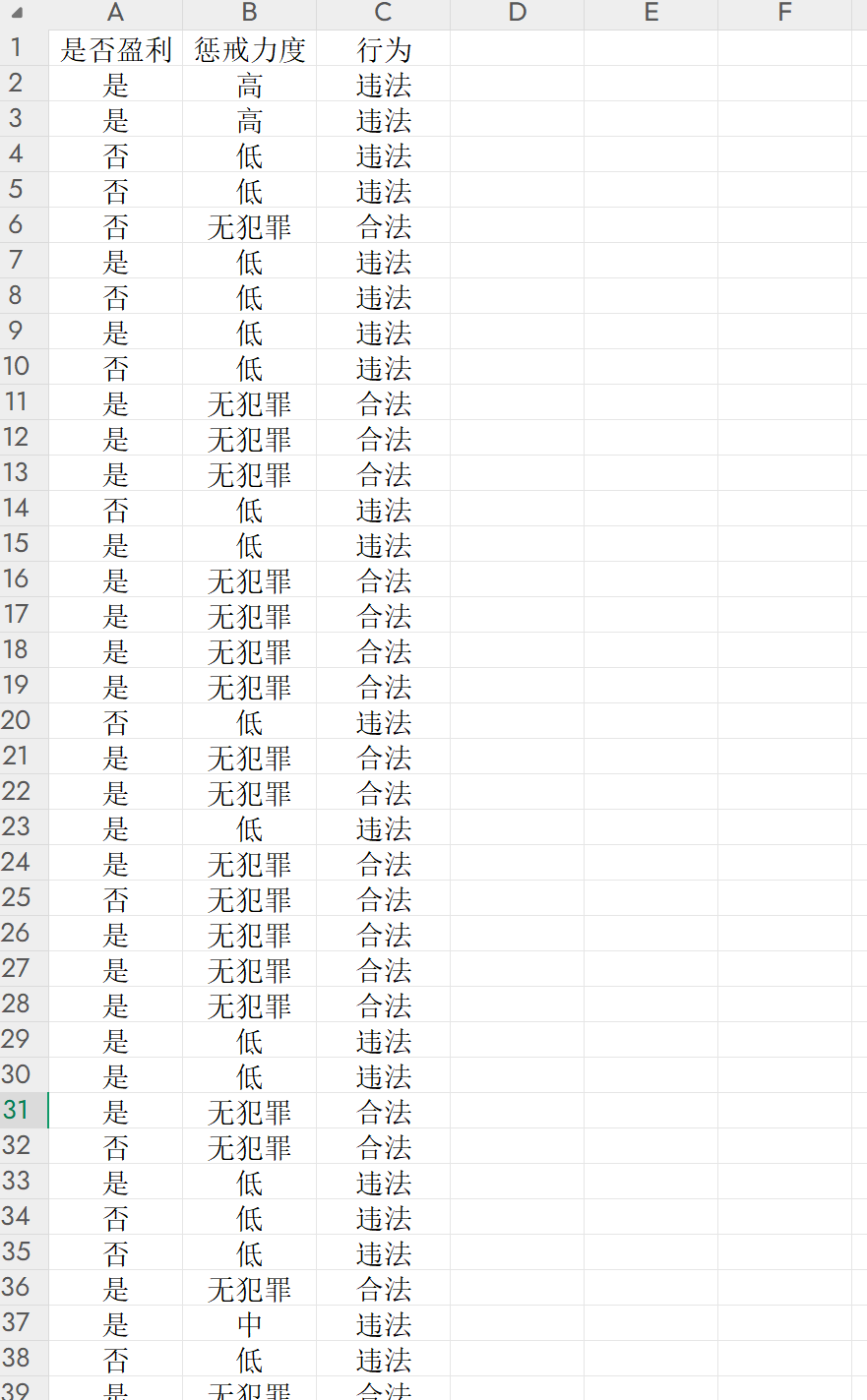

我想建立不同监管力度下企业行为的演变,但是好像变量里面出了一些问题导致我最后的预测准确度为百分之百了。
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你遇到的问题是决策树模型的预测准确度为百分之百,这可能是因为模型太简单或数据集太小导致的。以下是一些可能的解决方案:
以下是一个使用随机森林模型的示例代码:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf.fit(X_train, y_train)
# 评估模型
y_pred = rf.predict(X_test)
print("预测准确度:", accuracy_score(y_test, y_pred))
train_test_split 函数将数据集分割成训练集和测试集。RandomForestClassifier 类创建了一个随机森林模型,参数 n_estimators 设置了树的数量。fit 方法训练模型。predict 方法预测测试集的结果。accuracy_score 函数计算预测准确度。 分享 创建了问题
4月17日
创建了问题
4月17日


