让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
根据您提供的信息,问题可能出在数据预处理或分组计算环节。以下是解决方案和详细分析:
1. 数据预处理检查
首先确保原始数据格式正确。建议添加数据检查步骤:
# 检查原始数据结构
str(data)
summary(data)
# 检查转换后数据
head(clean_data)
table(clean_data$Indicator) # 检查指标分类是否正确
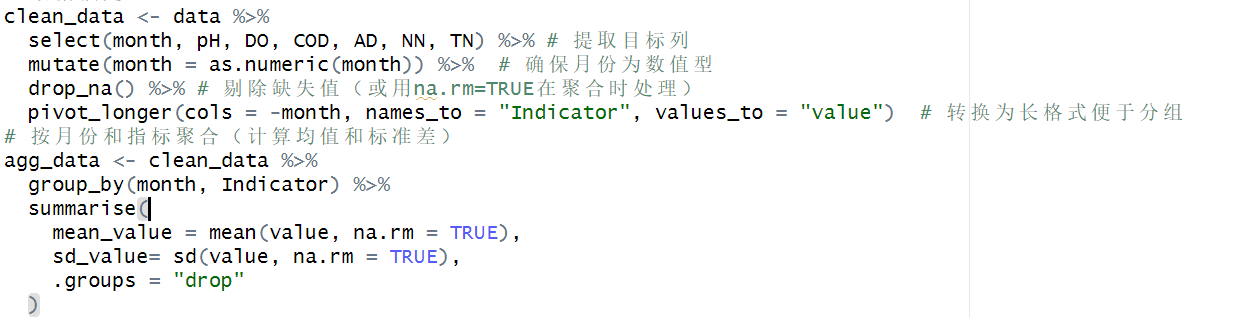
2. 修正的分组计算方案
当前代码可能因分组维度不足导致标准差为0。建议修改为:
agg_data <- clean_data %>%
group_by(month, Indicator) %>%
summarise(
mean_value = mean(value, na.rm = TRUE),
sd_value = sd(value, na.rm = TRUE),
n = n(), # 添加计数检查
.groups = "drop"
) %>%
filter(n > 1) # 排除单样本情况
3. 完整处理流程
建议采用以下完整处理流程:
library(tidyverse)
# 完整数据处理流程
water_quality_analysis <- function(data_path) {
# 读取数据
data <- read_csv(data_path)
# 数据预处理
clean_data <- data %>%
select(month, pH, DO, COD, AD, NN, TN) %>%
mutate(
month = as.numeric(month),
across(-month, as.numeric) # 确保所有指标为数值型
) %>%
pivot_longer(
cols = -month,
names_to = "Indicator",
values_to = "Value",
values_drop_na = TRUE
)
# 计算统计量
agg_data <- clean_data %>%
group_by(month, Indicator) %>%
summarise(
Mean = mean(Value),
SD = sd(Value),
Samples = n(),
.groups = "drop"
) %>%
mutate(
SD = ifelse(Samples < 2, NA, SD) # 处理单样本情况
)
return(agg_data)
}
# 使用示例
result <- water_quality_analysis("C:/Users/23316/Desktop/采样数据.csv")
print(result)
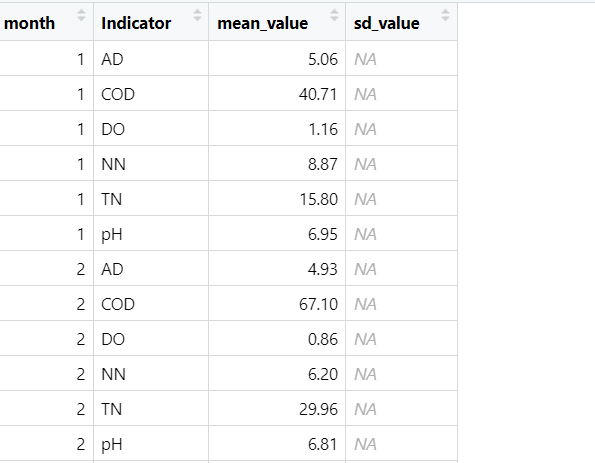
4. 常见问题排查
如果仍出现异常值,可能是以下原因:
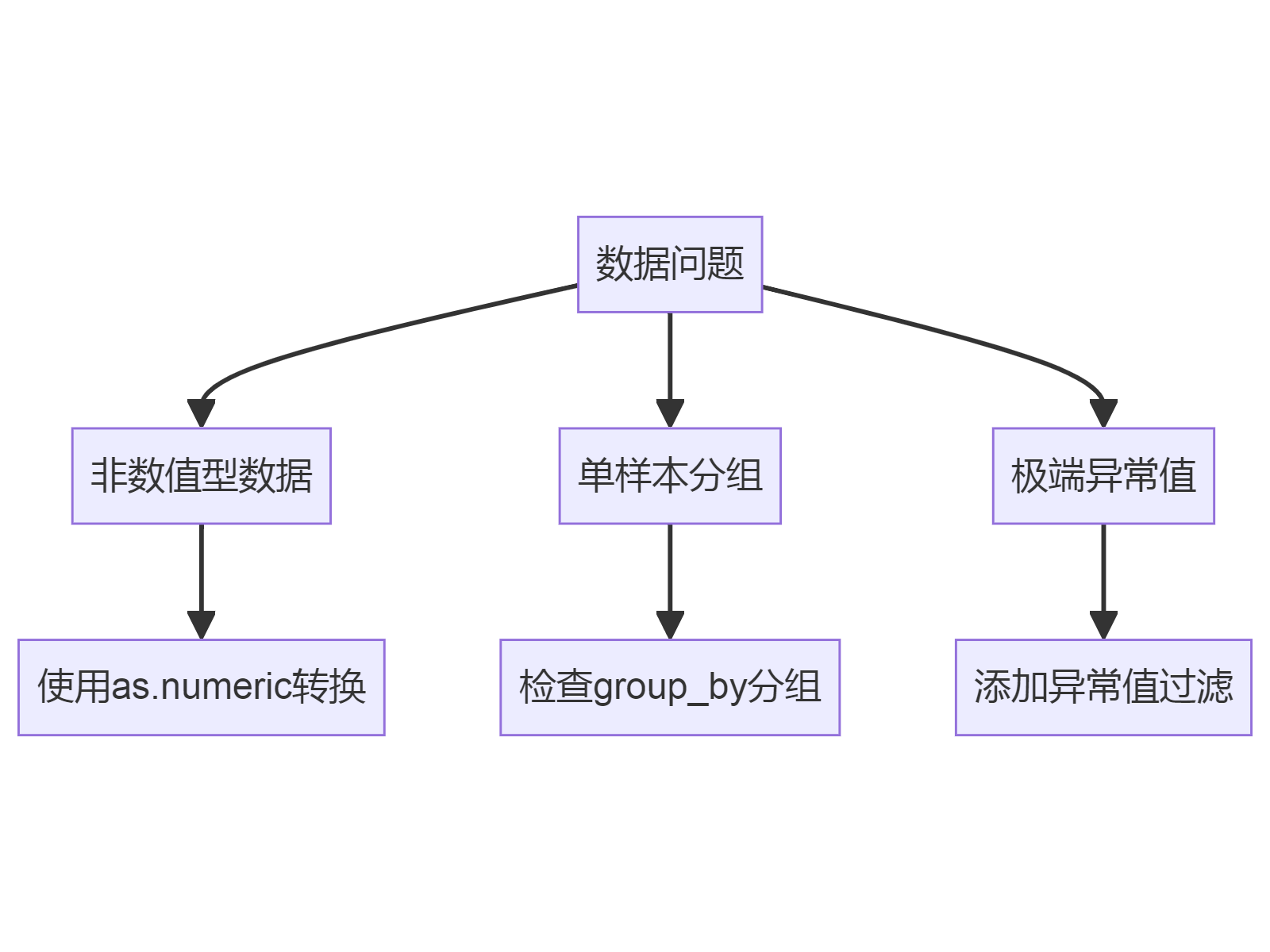
5. 可视化验证
最后建议用可视化验证结果:
ggplot(agg_data, aes(x=month, y=mean_value, color=Indicator)) +
geom_line() +
geom_errorbar(aes(ymin=mean_value-sd_value, ymax=mean_value+sd_value), width=0.2) +
facet_wrap(~Indicator, scales="free_y") +
labs(title="水质指标月变化趋势(均值±标准差)")
请特别注意:
- 确保原始数据中每个月份+指标组合有多于1个样本点
- 检查数据中是否存在非数值字符(如"NA"字符串)
- 如果仍有问题,建议先对单个指标进行测试排查