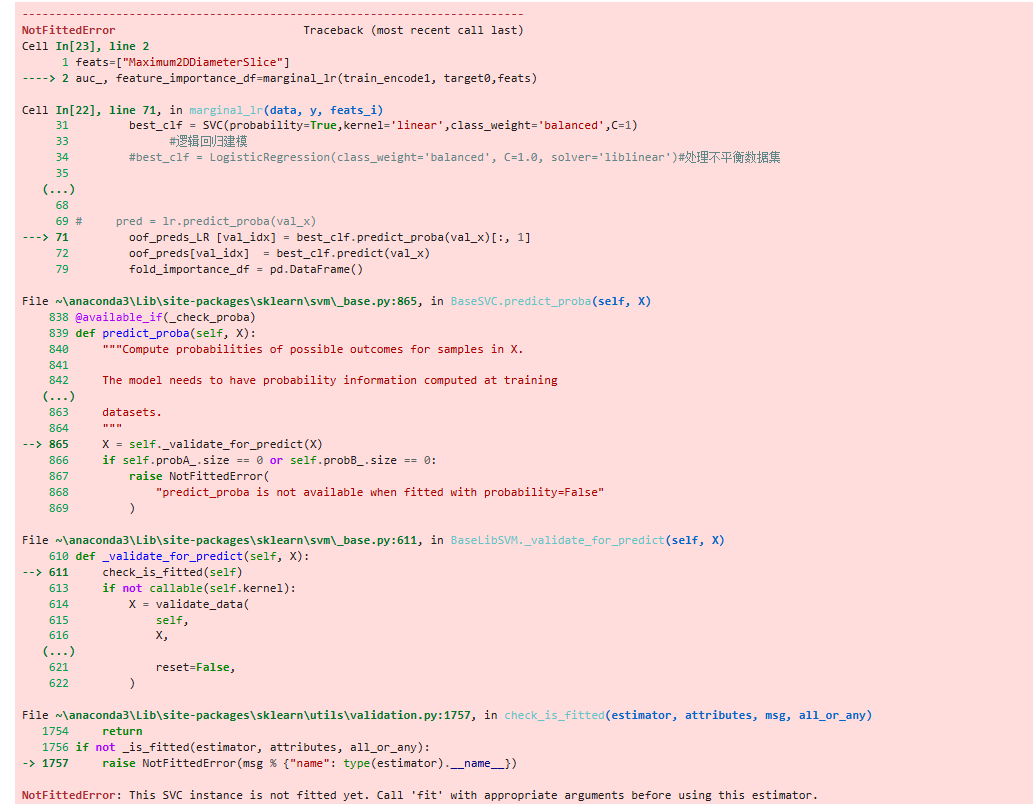
This SVC instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator. 是哪里出问题了呀?

This SVC instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator. 是哪里出问题了呀?
 分享
分享
 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
这个错误表明你在使用 SVC 模型时,没有先调用 fit() 方法进行训练就直接使用了 predict_proba() 方法进行预测。这是 scikit-learn 中常见的错误。
SVC 模型必须先通过 fit() 方法训练数据,才能使用预测方法(如 predict() 或 predict_proba())。best_clf = SVC(...) 创建模型后,直接调用了 best_clf.predict_proba(val_x),但中间缺少了 fit() 步骤。你需要在使用 predict_proba() 之前先调用 fit() 方法训练模型。修改后的代码结构应该是:
from sklearn.svm import SVC
# 1. 创建模型
best_clf = SVC(probability=True, kernel='linear', class_weight='balanced', C=1)
# 2. 训练模型(必须有这一步!)
best_clf.fit(train_x, train_y) # train_x是训练数据,train_y是标签
# 3. 然后才能预测
oof_preds_LR[val_idx] = best_clf.predict_proba(val_x)[:, 1]
根据你的错误堆栈,你应该修改 marginal_Ir 函数中的代码,确保在预测前先训练模型:
# 修改前的错误代码
best_clf = SVC(probability=True, kernel='linear', class_weight='balanced', C=1)
oof_preds_LR[val_idx] = best_clf.predict_proba(val_x)[:, 1] # 这里会报错
# 修改后的正确代码
best_clf = SVC(probability=True, kernel='linear', class_weight='balanced', C=1)
best_clf.fit(train_x, train_y) # 添加这行训练代码
oof_preds_LR[val_idx] = best_clf.predict_proba(val_x)[:, 1] # 现在可以正常预测
如果你是在做交叉验证,确保每个 fold 都重新训练模型:
for train_idx, val_idx in kf.split(data):
train_x, train_y = data.iloc[train_idx][feats_i], y[train_idx]
val_x = data.iloc[val_idx][feats_i]
# 每个fold都需要重新训练
best_clf = SVC(probability=True, kernel='linear', class_weight='balanced', C=1)
best_clf.fit(train_x, train_y) # 训练
# 然后预测
oof_preds_LR[val_idx] = best_clf.predict_proba(val_x)[:, 1]
记住:所有 scikit-learn 的模型都必须先 fit() 后 predict()!
分享 sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with app 完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with t3_Predicting the Markets w ML_sklearn_scatter_PairGrid_R-squared_log returns_Lasso_ridge_KNN_SVM_LR cp6_Model Eval_Confusion_Hyperpara Tuning_pipeline_variance_bias_ validation_learning curve_strength
sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with app 完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with t3_Predicting the Markets w ML_sklearn_scatter_PairGrid_R-squared_log returns_Lasso_ridge_KNN_SVM_LR cp6_Model Eval_Confusion_Hyperpara Tuning_pipeline_variance_bias_ validation_learning curve_strength 创建了问题
6月4日
创建了问题
6月4日
