
在A-LOAM特征提取中融合transformer自注意力机制使其在KITTI数据集00序列的表现更优,或者有其他方法可以改进A-LOAM,愿意参纳(有偿)


6条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
改进A-LOAM在KITTI数据集00序列的优化方案
针对您提出的改进A-LOAM在KITTI 00序列表现的需求,我将提供几种可行的优化方案,包括融合Transformer自注意力机制的方法以及其他改进方向。
1. 融合Transformer自注意力机制的方案
1.1 特征提取模块改进
在A-LOAM的特征提取阶段,可以引入Transformer来增强点云特征的表达能力:
import torch import torch.nn as nn from einops import rearrange class PointCloudTransformer(nn.Module): def __init__(self, dim=64, depth=2, heads=4, dim_head=32): super().__init__() self.to_patch_embedding = nn.Sequential( nn.Linear(3, dim), nn.GELU(), nn.Linear(dim, dim) ) self.transformer = nn.TransformerEncoder( nn.TransformerEncoderLayer(d_model=dim, nhead=heads), num_layers=depth ) def forward(self, x): # x: (B, N, 3) x = self.to_patch_embedding(x) # (B, N, dim) x = self.transformer(x) # (B, N, dim) return x1.2 改进后的特征提取流程
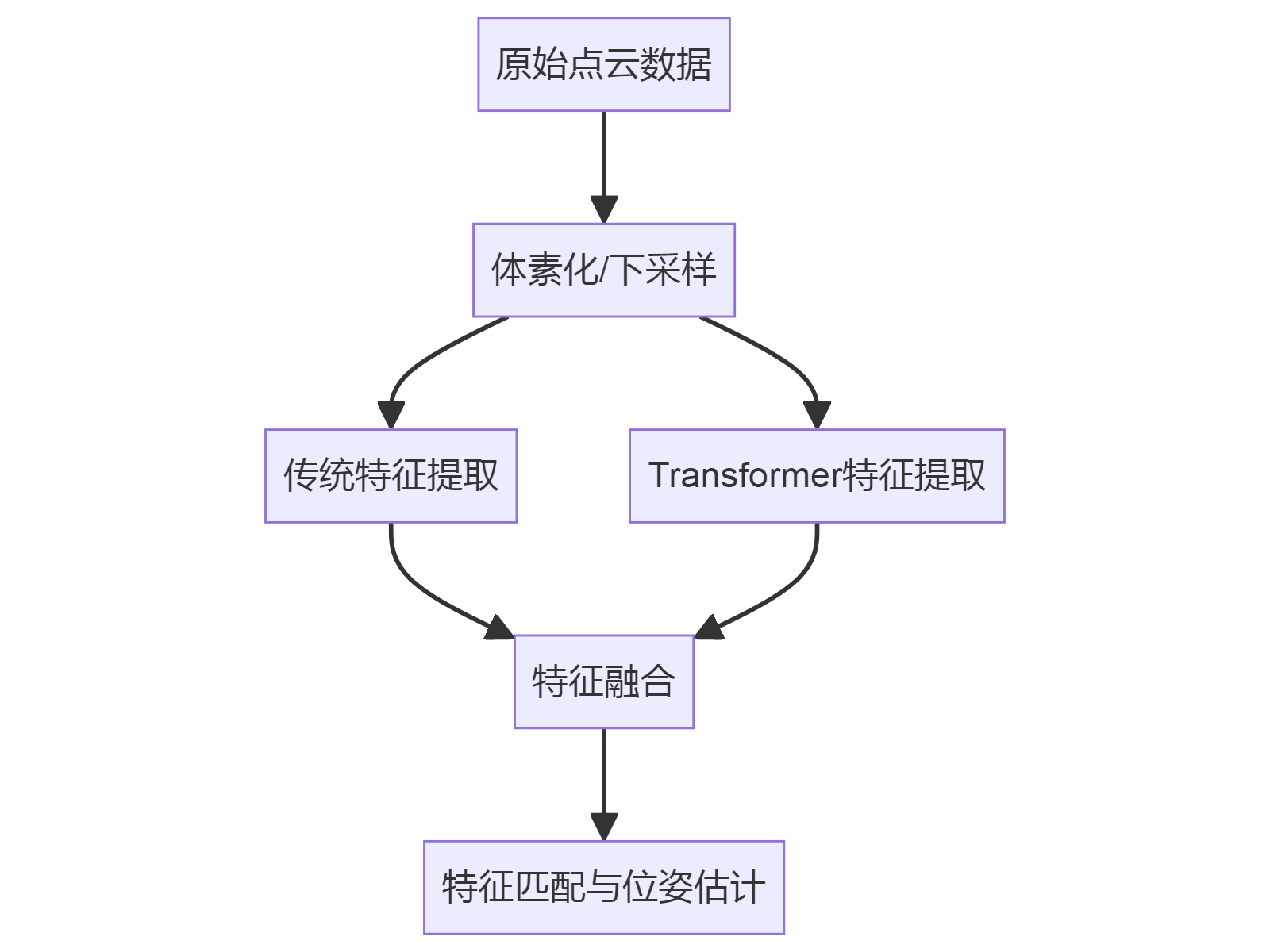
2. 其他改进A-LOAM的方法
2.1 动态特征权重调整
class DynamicFeatureWeight(nn.Module): def __init__(self, in_channels): super().__init__() self.conv = nn.Sequential( nn.Conv1d(in_channels, in_channels//2, 1), nn.BatchNorm1d(in_channels//2), nn.ReLU(), nn.Conv1d(in_channels//2, 1, 1), nn.Sigmoid() ) def forward(self, x): # x: (B, C, N) weights = self.conv(x) # (B, 1, N) return x * weights2.2 时序一致性优化
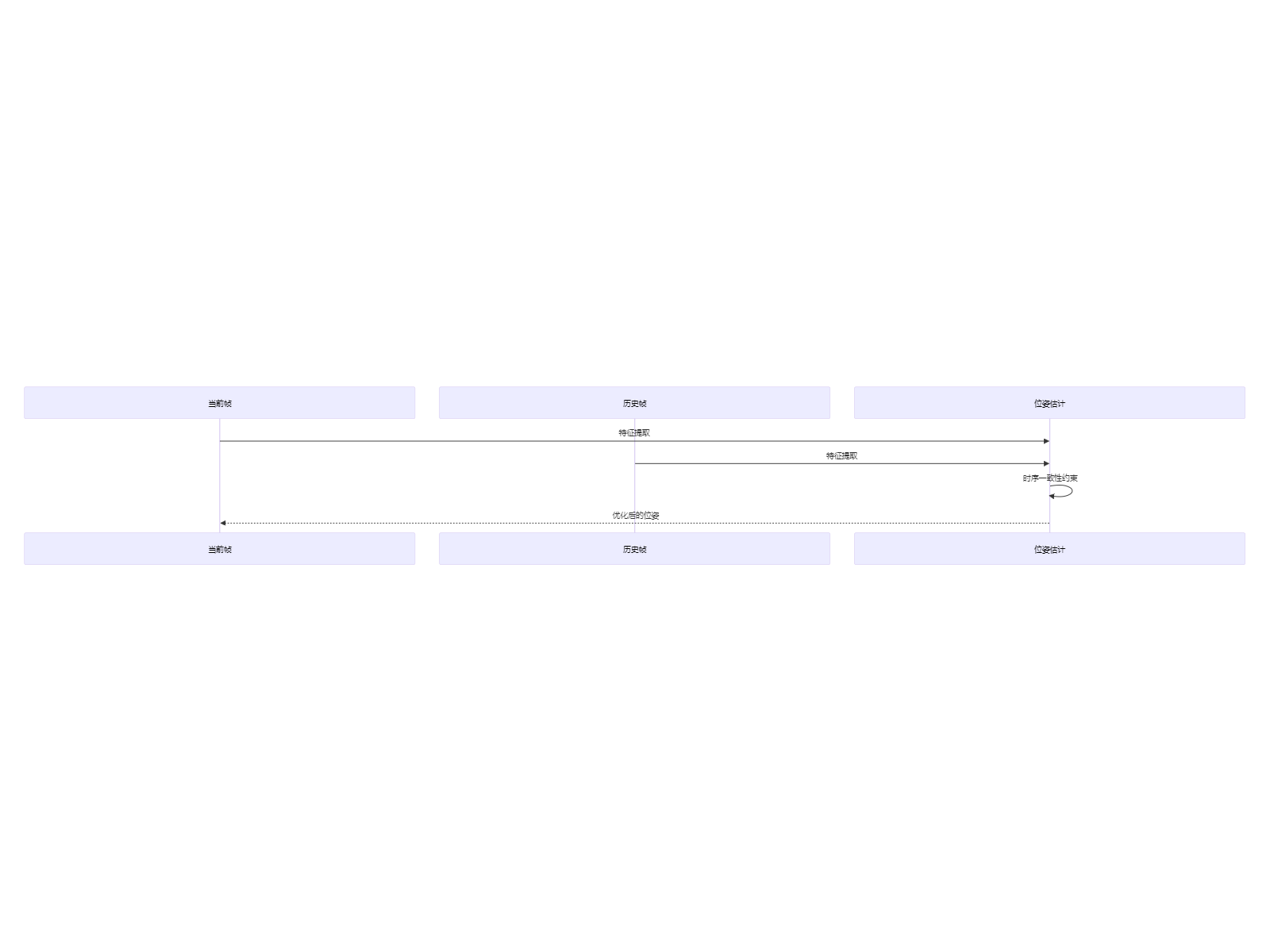
2.3 基于KITTI 00序列的特定优化
- 地面点优化:针对KITTI数据集中地面占比较大的特点
- 动态物体过滤:增强对移动车辆的鲁棒性
- 回环检测增强:结合视觉或点云描述子
3. 实施建议
- 评估指标:建议使用ATE(Absolute Trajectory Error)和RPE(Relative Pose Error)作为主要评估指标
- 分阶段实施:先验证Transformer模块的有效性,再逐步集成其他优化
- 硬件需求:Transformer模块会增加计算量,建议使用GPU加速
4. 有偿合作说明
如果您需要更深入的技术支持或完整的实现,我们可以提供:
- 完整的代码实现与部署
- 针对KITTI 00序列的定制优化
- 性能评估与调优服务
您可以根据实际需求选择最适合的优化方案组合。建议先从Transformer特征融合开始尝试,因为这是提升特征表达能力的直接方法。
解决 无用评论 打赏举报 分享
分享
- 2022-07-23 17:25点云PCL公众号博客的博客 文章:PaGO-LOAM: Robust Ground-Optimized LiDAR Odometry作者:Dong-Uk Seo , Hyungtae Lim , Seungjae Lee , and Hyun Myung ,编译:点云PCL代码:https://github.com/url-kaist/AlterGround-LeGO-LOAM.git...
- 2025-10-21 01:44c6d7e8f9g的博客 本文针对LEGO-LOAM融合IMU数据后出现的轨迹漂移问题,提供了从根源分析到实战调优的完整解决方案。文章深入剖析了传感器标定、时间同步及参数配置等关键因素,并详细介绍了如何使用EVO工具进行科学的轨迹评估与对比...
- 2025-10-22 04:12gold的博客 本文提供了一份ROS bag文件从录制到播放...通过详细讲解录制、查看与播放的核心命令与高级技巧,并结合A-LOAM激光SLAM案例,深入演示了如何利用bag文件进行高效的算法调试与数据回放,是提升机器人开发效率的关键技能。
- 2021-07-22 12:00点云PCL公众号博客的博客 文章:SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure作者:Lin Li1 , Xin Kong1 , Xiangrui Zhao1...
- 2022-07-01 07:003D视觉工坊的博客 基于学习的SLAM系统中,Droid-slam是所有SLAM中定位精度最高,其在TUM-RGBDI和EuRoC上的性能远超ORB-SLAM3,它在所有的序列上都能达到厘米级的精度,其缺点在于非常消耗计算资源,需要两块3090才能实时运行;...
- 2021-07-07 01:00点云PCL公众号博客的博客 文章:F-LOAM : Fast LiDAR Odometry and Mapping作者:Han Wang, Chen Wang, Chun-Lin Chen, and Lihua Xi...
- 2022-10-13 07:003D视觉工坊的博客 引言近年来,多传感器融合算法发展迅猛,不同传感器可以相互补充,通过...但受限于标定成本和时间同步问题,多传感器数据集却不多。在2022 IROS论文"FusionPortable: A Multi-Sensor Campus-Scene Dataset for Eva...
- 2025-10-16 02:50杠精协会主席的博客 本文提供了NCLT数据集从传感器配置到数据预处理的完整实战指南。详细解析了其多传感器系统(激光雷达、全景相机、IMU)的规格、标定参数,特别是相机畸变处理的特殊方法。文章还涵盖了数据下载策略、关键预处理步骤...
- 2022-07-27 07:003D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达作者丨汽车人来源丨自动驾驶之心多任务学习是自动驾驶领域非常重要的一个模块,旨在通过一个网络在较小计算量下实现多个任务,比如分割、检测、关键点、车道线...
- 2026-03-11 00:06白追追的博客 本文针对在KITTI数据集上运行FAST-LIO2和Point-LIO等现代激光雷达惯性里程计(LIO)算法时,因点云数据缺失时间戳字段而报错‘Failed to find match for field ‘time‘’的问题,提供了深度解析与实战解决方案。...
- 2022-07-29 07:003D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达作者丨汽车人来源丨自动驾驶之心 论文标题:Outdoor Monocular Depth Estimation: A Research Review论文链接:https://arxiv.org/pdf/2205....
- 2021-10-23 00:003D视觉工坊的博客 下面两张表给出了在KITTI上3D检测的对比结果以及动态检测模型。 A)基于2D的序列模型 所谓基于2D的序列模型,就是首先对图片进行2D检测/分割,生成ROI区域,然后将ROI投影到3D空间中(将图像上的边界框投影到点云上...
- 2022-01-29 07:003D视觉工坊的博客 在KITTI数据集上,每帧大约生成40K(车辆)或70K(行人和自行车)个候选框。这些3D候选框投影到图像坐标后,通过2D图像上特征进行评分。这些特征来自语义分割,实例分割,上下文,形状以及位置先验信息。所有这些...
- 2024-08-11 00:023D视觉工坊的博客 在640×192分辨率下,使用原始真实值和改进后的真实值在KITTI数据集上进行定量比较的结果分别列于表1和表2中。显然,我们的方法结合D-HRNet可以实现最先进的性能。此外,我们的Mono-ViFI在不增加模型复杂度的情况下...
- 2024-04-12 07:003D视觉工坊的博客 本文提出了VOLoc,一种准确高效的视觉地点识别方法,利用几何相似性直接通过实时捕获的图像序列查询压缩的激光雷达地图。在离线阶段,VOLoc使用几何保持压缩器(GPC)压缩激光雷达地图,其中压缩是可逆的,这是下游6...
- 2024-10-10 09:553D视觉工坊的博客 我们在三个具有挑战性的数据集上的实验:KITTI、EuRoC和KAIST-VIO,以及两个高度精确的SLAM后端:Full-BA和ICE-BA表明,Jetson-SLAM是可用的最快的精确和GPU加速SLAM系统。 2. 引言 厘米级精度的局部定位系统对于复杂...
- 2020-08-08 00:003D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达SLAM包含两个主要任务,定位和建图。这是移动机器人自主完成作业任务需要解决的基本问题,特别是在未知环境的情况下,移动机器人既要确定...
- 2024-07-03 07:043D视觉工坊的博客 因此,我们在图8中展示了我们的方法在KITTI和Waymo数据集上的有效性和鲁棒性,这些数据集展示了更复杂和更大的相机运动。我们还在表II中展示了估计的相机姿态的定量结果。我们发现,在Waymo数据集中,我们方法的估计...
- 2024-03-24 00:003D视觉工坊的博客 在本文中,我们介绍了一种利用3D高斯喷涂的新型管道,用于全面理解城市场景。我们的主要想法涉及使用静态和动态3D高斯的组合,通过物理约束对移动物体姿态进行正则化,从而联合优化几何、外观、语义和运动。
- 2020-11-05 07:003D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达标题: A Robust Laser-Inertial Odometry and Mapping Method for Large-...
- 没有解决我的问题, 去提问

问题事件
 创建了问题
6月11日
创建了问题
6月11日