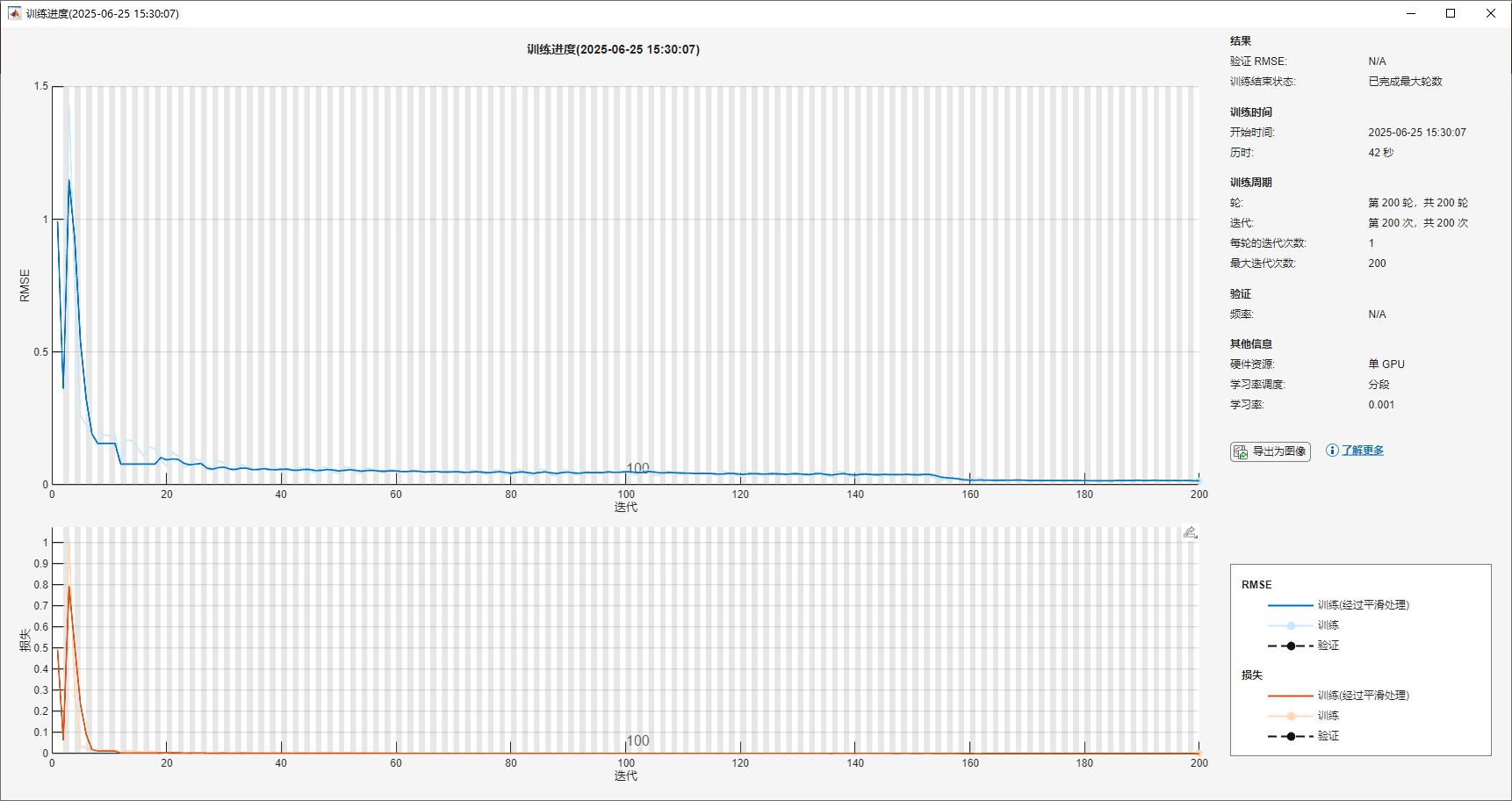
为什么LSTM训练损失一下就到0了啊,但是预测出来差距又比较大。想半天了也没发现有啥问题。
% 清除工作区和命令窗口
clc
clear
% 加载时序数据 - 该数据包含5119个时间步的观测值
load shiqusudushijian.mat
data = matrix_data(2,:); % 提取第二行数据作为目标序列
data(data == 0) = []; % 移除数据中的零值
%% 数据划分 - 前5000个样本用于训练,后119个样本用于测试
dataTrain = data(1:5000); % 定义训练数据集
dataTest = data(5001:5119); % 定义测试数据集,用于评估模型性能
%% 数据标准化处理 - 使用训练集的统计量进行标准化
mu = mean(dataTrain); % 计算训练数据的均值
sig = std(dataTrain); % 计算训练数据的标准差
dataTrainStandardized = (dataTrain - mu) / sig; % 标准化训练数据
%% 构建训练序列 - 使用t时刻的值预测t+1时刻的值
XTrain = dataTrainStandardized(1:end-1); % 输入序列:t时刻的值
YTrain = dataTrainStandardized(2:end); % 目标序列:t+1时刻的值
%% 构建LSTM回归模型架构
numFeatures = 1; % 输入特征维度为1(单变量时间序列)
numResponses = 1; % 输出维度为1(预测下一个时间步的值)
numHiddenUnits = 100; % LSTM层的隐藏单元数量,控制模型复杂度
layers = [
sequenceInputLayer(numFeatures) % 序列输入层,接收时序数据
lstmLayer(numHiddenUnits) % LSTM层,学习时序数据中的模式
fullyConnectedLayer(numResponses) % 全连接层,映射LSTM输出到预测值
regressionLayer % 回归层,用于连续值预测
];
%% 配置训练选项
options = trainingOptions('adam', ...
'MaxEpochs', 200, ... % 最大训练轮数
'GradientThreshold', 0.8, ... % 梯度裁剪阈值,防止梯度爆炸
'InitialLearnRate', 0.01, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 分段学习率策略
'LearnRateDropPeriod', 150, ... % 学习率下降周期
'ValidationFrequency', 50, ... % 验证频率
'Shuffle', 'every-epoch', ... % 每轮训练打乱数据顺序
'Verbose', 1, ... % 显示训练进度信息
'Plots', 'training-progress'); % 显示训练进度图
%% 训练LSTM模型
net = trainNetwork(XTrain, YTrain, layers, options);
%% 初始化网络状态 - 使用训练数据的最后一个值作为预测起点
net = predictAndUpdateState(net, XTrain); % 初始化网络状态
[net, YPred] = predictAndUpdateState(net, YTrain(end)); % 预测第一个未来值
%% 递归预测未来119个时间步的值
for i = 2:119
% 使用前一个预测值更新网络状态并预测下一个值
[net, YPred(:,i)] = predictAndUpdateState(net, YPred(:,i-1), 'ExecutionEnvironment', 'cpu');
end
%% 评估模型性能并可视化结果
YPred = sig * YPred + mu; % 将预测结果反标准化到原始数据尺度
% 计算均方根误差 (RMSE)
rmse = sqrt(mean((YPred(1:119) - dataTest).^2));
% 绘制训练数据和预测结果
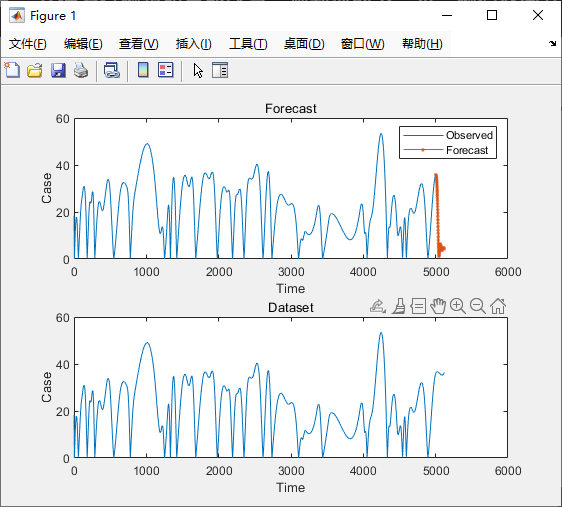
subplot(2,1,1)
plot(dataTrain(1:end)) % 绘制训练数据
hold on
idx = 5001:(5119); % 测试数据的时间索引
plot(idx, YPred(1:119), '.-') % 绘制预测结果
hold off
xlabel("Time")
ylabel("Case")
title("Forecast")
legend(["Observed" "Forecast"])
% 绘制完整数据集
subplot(2,1,2)
plot(data)
xlabel("Time")
ylabel("Case")
title("Dataset")
%% 详细比较预测值与实际测试数据
dataTestStandardized = (dataTest - mu) / sig; % 标准化测试数据
XTest = dataTestStandardized(1:end-1); % 测试输入序列
YTest = dataTest(1:end); % 实际测试值
% 可视化预测结果与误差
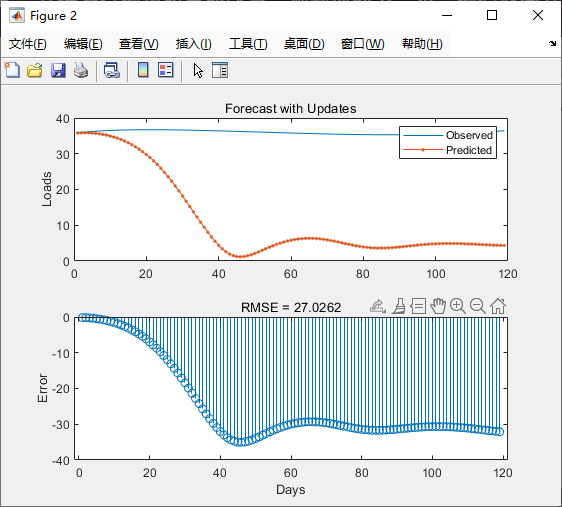
figure
subplot(2,1,1)
plot(YTest) % 绘制实际测试值
hold on
plot(YPred, '.-') % 绘制预测值
hold off
legend(["Observed" "Predicted"])
ylabel("Loads")
title("Forecast with Updates")
% 绘制预测误差
subplot(2,1,2)
stem(YPred - YTest) % 绘制预测误差
xlabel("Days")
ylabel("Error")
title("RMSE = " + rmse) % 显示均方根误差