
想咨询一个问题,在目标检测任务中,可以将预测每个类别的概率sofamax一下,然后利用知识蒸馏的逻辑蒸馏,教师模型可以提高学生模型的检测效果,我想问一下语义分割中,这个东西还可以用吗,怎么做逻辑蒸馏?有没有相应文章推荐呢?


5条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
若您愿意支持,欢迎直接打赏,将不胜感激!
语义分割中的知识蒸馏方法
语义分割任务中确实可以应用知识蒸馏技术,而且逻辑蒸馏(Logits Distillation)的思想可以很好地迁移到语义分割任务中。下面我将详细介绍实现方法和相关研究。
语义分割中的知识蒸馏原理
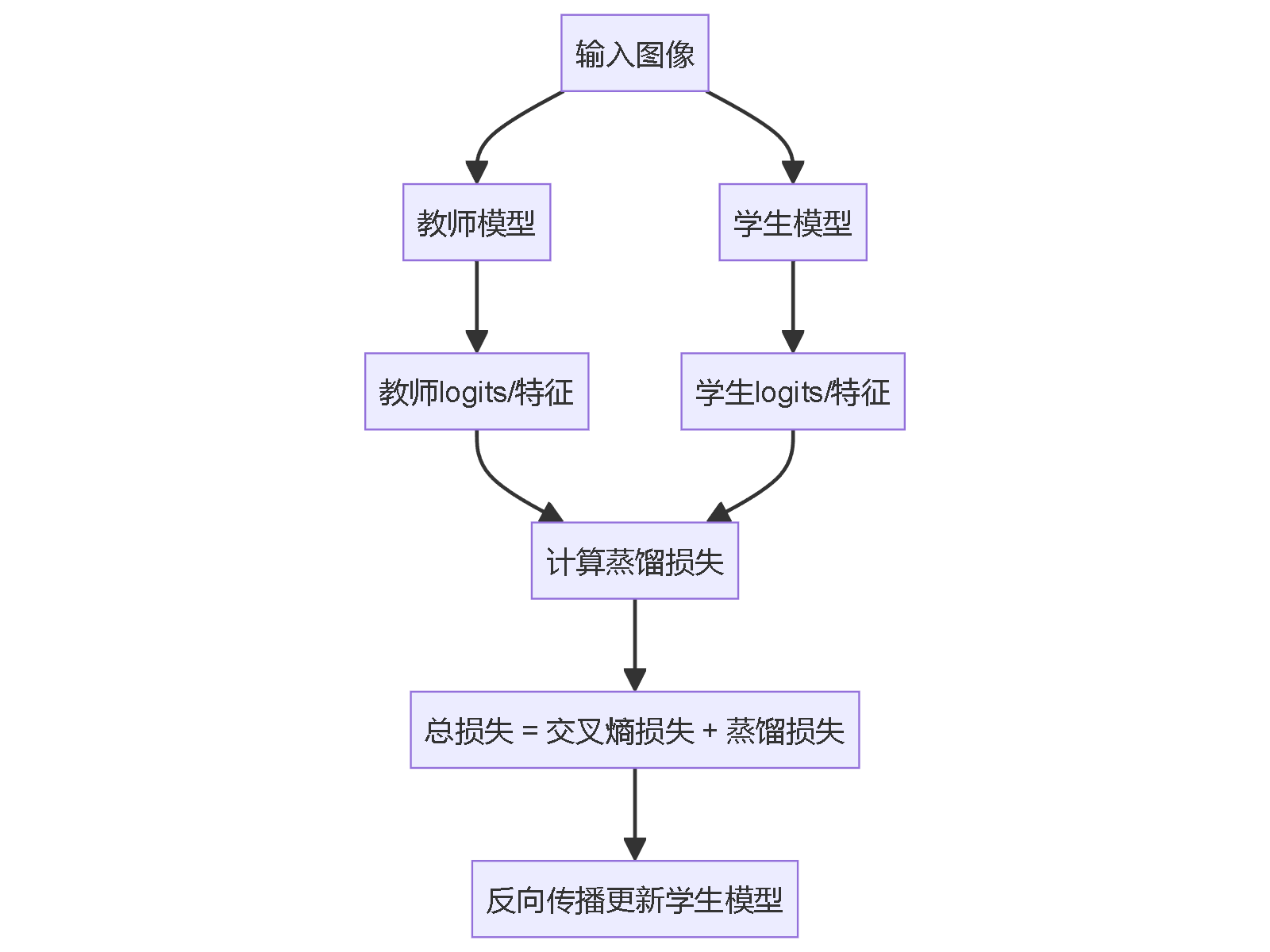
在语义分割中,知识蒸馏的核心思想与目标检测类似,都是让教师模型的输出(通常是softmax后的概率分布)指导学生模型的训练。不同之处在于语义分割是对每个像素点进行分类,因此蒸馏是在像素级别进行的。
基本实现方法
import torch import torch.nn as nn import torch.nn.functional as F class SegmentationDistillLoss(nn.Module): def __init__(self, alpha=0.5, temperature=3): super().__init__() self.alpha = alpha # 蒸馏损失权重 self.temperature = temperature self.ce_loss = nn.CrossEntropyLoss() def forward(self, student_logits, teacher_logits, labels): # 常规交叉熵损失 ce_loss = self.ce_loss(student_logits, labels) # 蒸馏损失 soft_teacher = F.softmax(teacher_logits / self.temperature, dim=1) soft_student = F.log_softmax(student_logits / self.temperature, dim=1) distill_loss = F.kl_div(soft_student, soft_teacher, reduction='batchmean') * (self.temperature ** 2) # 总损失 total_loss = (1 - self.alpha) * ce_loss + self.alpha * distill_loss return total_loss语义分割知识蒸馏流程
进阶蒸馏方法
除了基本的逻辑蒸馏外,语义分割中还有以下几种常用方法:
- 特征蒸馏:在中间层对齐教师和学生模型的特征图
- 关系蒸馏:捕捉像素间的关系信息
- 结构化蒸馏:考虑分割任务的结构化特性
推荐论文
- 《Structured Knowledge Distillation for Semantic Segmentation》 (CVPR 2019)
- 提出结构化知识蒸馏,考虑像素间关系
- 《Knowledge Distillation via Instance Relationship Graph》 (CVPR 2019)
- 使用实例关系图进行蒸馏
- 《Knowledge Adaptation for Efficient Semantic Segmentation》 (CVPR 2019)
- 针对高效语义分割的知识适应方法
- 《Pixel-wise Knowledge Distillation for Dense Prediction》 (TPAMI 2021)
- 像素级别的知识蒸馏框架
- 《Distilling Cross-Task Knowledge via Relationship Matching》 (CVPR 2020)
- 通过关系匹配进行跨任务知识蒸馏
实践建议
- 温度参数调节:通常设置在3-5之间,需要根据任务调整
- 损失权重平衡:蒸馏损失和常规损失的权重需要调优
- 多阶段蒸馏:可以结合逻辑蒸馏和特征蒸馏
- 教师模型选择:教师模型不宜过于复杂,与学生模型差距不宜过大
语义分割中的知识蒸馏已经证明能有效提升小模型的性能,特别是在边缘设备部署场景下非常有用。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2024-03-16 15:12随着人工智能领域的快速发展,尤其是计算机视觉技术的进步,多模态语义分割与知识蒸馏技术成为了研究热点。这两种技术不仅在学术界引起了广泛关注,在工业界的诸多应用场景中也展现出了巨大潜力。本文将详细介绍多...
- 2025-06-10 10:31AIGC应用创新大全的博客 本文旨在为读者提供知识蒸馏在语义分割领域应用的全面指南,包括核心概念、实现方法和性能优化技巧。我们将重点讨论如何通过蒸馏技术将大型教师模型的知识迁移到小型学生模型中,同时保持较高的分割精度。文章首先...
- 2019-03-16 08:50AI科技大本营的博客 作者 | CV君来源 | 我爱计算机视觉今天跟大家分享一篇关于语义分割的论文,刚刚上传到arXiv的CVPR 2019接收论文《Structured Knowledge ...
- 2023-04-01 14:17小杨小杨1的博客 采用显著图(saliency map)方法从卷积神经网络中提取有用的蒸馏知识通过制作特定类的注意图,然后强迫学生网络模拟产生这些注意一种利用特定类注意图进行注意力转移的新方法介绍了该方法能够成功地从两个网络的中间...
- 2026-01-08 22:17个人语义分割论文归档与知识管理系统是一个综合性资源库,它的创建基于深度学习与传统经典语义分割、全景分割、前景背景分割、知识蒸馏、迁移学习等相关领域的学术论文。这个系统化收集整理和归档的研究平台,主要...
- 2019-03-13 18:45SophiaCV的博客 点上方蓝字计算机视觉联盟获取更多干货在右上方···设为星标★,与你不见不散今天介绍一篇来自阿德莱德大学、亚洲微软研究院、北航的CVPR2019关于语义分割的论文。本...
- 2025-02-08 09:17【3】本项目适合计算机相关专业(人工智能、通信工程、自动化、电子信息、物联网等)的高校学生、教师、科研工作者、行业从业者下载使用,可借鉴学习,也可直接作为毕业设计、课程设计、作业、项目初期立项演示等,也...
- 2023-02-14 23:14長 安的博客 当前用于语义分割的知识蒸馏(KD)方法通常指导学生模仿教师从个人数据样本生成的结构化信息。但是,它们忽略了对 KD 有价值的各种图像中像素之间的全局语义关系。该文提出一种新型的跨图像关系KD(CIRKD),该算法...
- 2024-05-26 05:51AI智韵的博客 知识蒸馏已成功应用于各种任务。当前的蒸馏算法通常通过模仿教师的输出来提高学生的性能。本文表明,教师还可以通过指导学生的特征恢复来提高学生的表示能力。从这一观点出发,我们提出了掩码生成蒸馏(Masked ...
- 2024-10-08 20:08Humburger_Sun的博客 由于神经网络容量与知识量不一致,导致基于知识蒸馏的无监督异常分割方法出现过拟合的问题,并没有受到重视。本文提出一种信息性知识蒸馏方法(IKD),通过提取信息性知识并提供强监督信号来解决过拟合问题。提出了...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
7月22日
系统已结题
7月22日 已采纳回答
7月14日
已采纳回答
7月14日-
创建了问题
7月12日