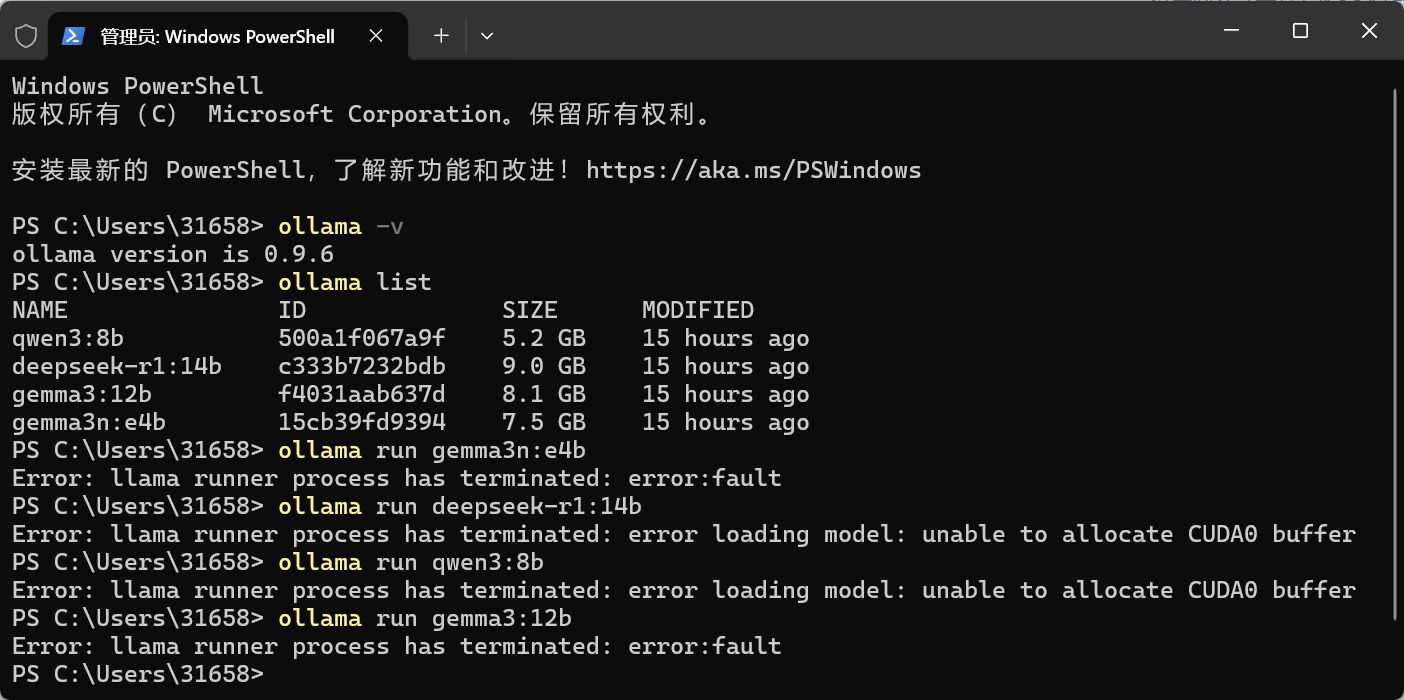
启动ollama中的模型出现
Error: llama runner process has terminated: error:fault
Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer
的错误提示,要怎么解决

启动ollama中的模型出现
Error: llama runner process has terminated: error:fault
Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer
的错误提示,要怎么解决
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
你遇到的错误提示:
Error: llama runner process has terminated: error:fault
Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer
这个错误通常发生在 Ollama 启动模型时,无法在CUDA设备上分配内存资源。以下是详细的原因分析和解决方案。
显卡内存不足(CUDA memory allocation failure)
CUDA驱动或库版本不兼容
系统资源限制
ulimit设置过低。Ollama配置问题
使用以下命令查看GPU是否正常工作:
nvidia-smi
重点:确保GPU驱动和CUDA版本与Ollama兼容。
如果你的GPU显存较小,可以考虑:
修改Ollama配置文件(通常位于 ~/.ollama/models/ 或 /etc/ollama/),将模型加载方式改为CPU模式。
或者在启动Ollama时通过环境变量禁用CUDA:
CUDA_VISIBLE_DEVICES=-1 ollama serve
重点:通过设置
CUDA_VISIBLE_DEVICES=-1可强制Ollama使用CPU,避免CUDA内存分配错误。
如果模型过大,可以尝试加载一个更小的模型,例如:
ollama run llama2:7b
而不是:
ollama run llama2:13b
重点:选择合适的模型大小,避免超过GPU显存限制。
如果是因为系统限制了内存使用,可以临时提升限制:
ulimit -s unlimited
或者编辑 /etc/security/limits.conf 添加:
* soft memlock unlimited
* hard memlock unlimited
重点:提高系统对内存的限制有助于缓解CUDA内存分配问题。
确保你的CUDA和NVIDIA驱动是最新的:
sudo apt update && sudo apt upgrade nvidia-driver-<version>
或者从 NVIDIA官网 下载最新驱动。
重点:旧版CUDA可能导致Ollama无法正确分配显存。
查看Ollama的日志以获取更详细的错误信息:
journalctl -u ollama.service
或者直接运行Ollama时添加调试信息:
ollama serve --log-level debug
重点:日志中可能包含具体内存分配失败的位置,便于定位问题。
如果你使用的是自定义启动脚本,可以这样修改:
#!/bin/bash
# 强制使用CPU,避免CUDA内存分配失败
export CUDA_VISIBLE_DEVICES=-1
ollama serve
保存为 start_ollama.sh,然后运行:
chmod +x start_ollama.sh
./start_ollama.sh
nvidia-smi 确保GPU正常工作。CUDA_VISIBLE_DEVICES=-1 强制Ollama使用CPU。ulimit -s unlimited。如有更多关于Ollama的问题,欢迎继续提问!
分享 创建了问题
7月15日
创建了问题
7月15日


