让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
- 问题关键点分析:
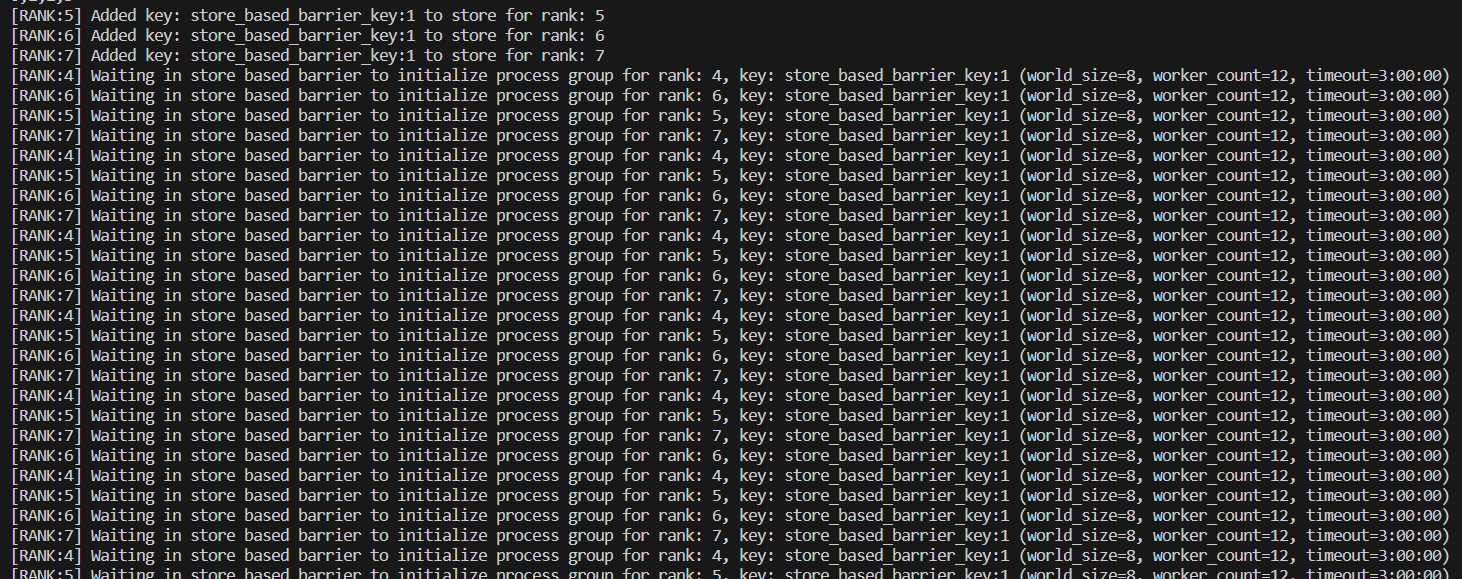
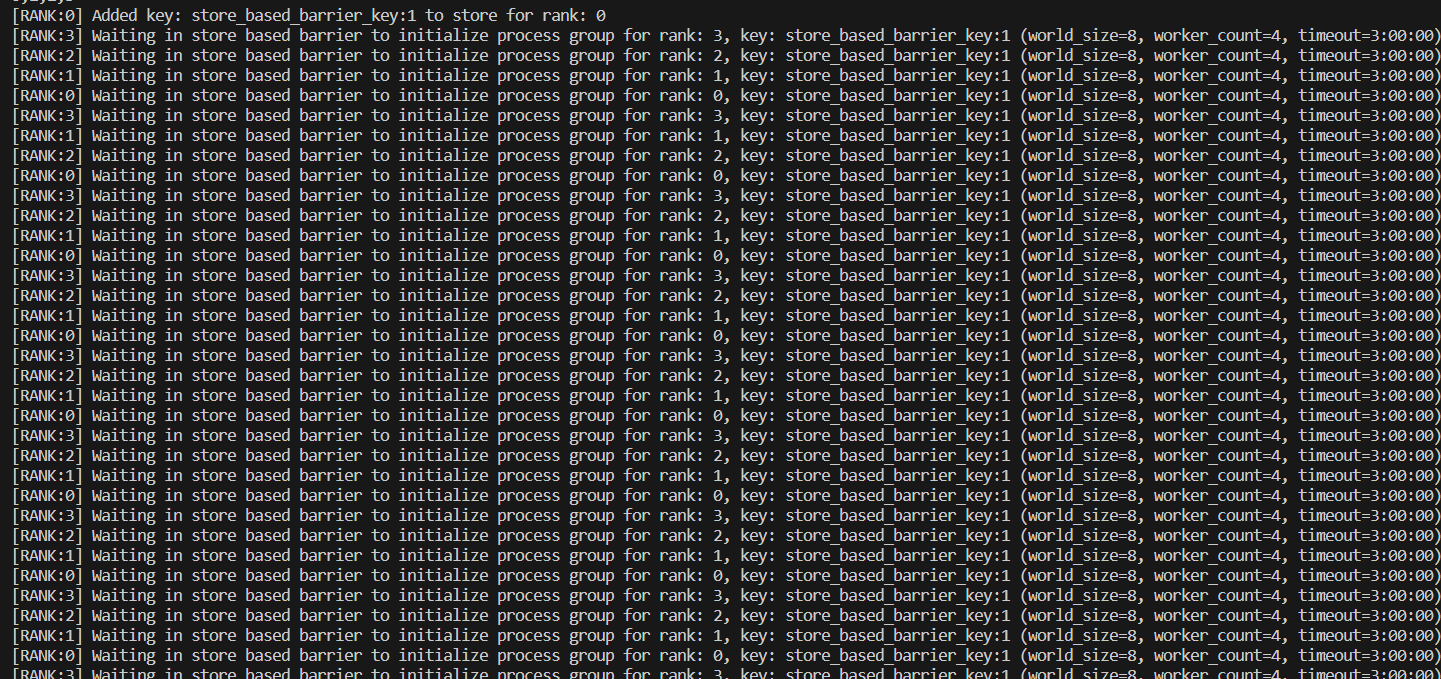
- 从描述来看,单机多卡训练正常,而多机多卡训练出现问题但未详细说明具体现象。可能的关键点在于多机之间的通信、设备同步、数据分发等方面。例如,不同机器上的进程如何协调工作,如何确保每张卡都能正确获取到对应的训练数据和模型参数等。 -
解决方案:
- 环境配置:
- 确保所有机器的操作系统、CUDA版本、Python版本等一致。例如,在所有机器上安装相同版本的CUDA 11.3和Python 3.8。
- 安装相同版本的深度学习框架,如PyTorch 1.9.0。可以通过以下命令安装:
bash
pip install torch==1.9.0+cu113 torchvision==0.10.0+cu113 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html - 网络配置:
- 所有机器需要在同一个局域网内,并且配置好内部网络,保证机器之间能够互相通信。可以通过ping命令测试机器之间的连通性。
- 检查防火墙设置,确保允许相关的网络端口通信。例如,对于PyTorch的分布式训练,通常需要开放TCP端口。
- 代码修改:
- 以PyTorch为例,在训练脚本中初始化分布式环境。假设使用
torch.distributed.launch来启动训练,可以参考以下代码:
```python
import torch
import torch.distributed as dist
def setup(rank, world_size):
os.environ[‘MASTER_ADDR’] = ‘localhost’
os.environ[‘MASTER_PORT’] = ‘12355’
dist.init_process_group(“nccl”, rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
if name == ‘main’:
world_size = 2 # 假设两台机器
for rank in range(world_size):
setup(rank, world_size)
# 这里放置你的训练代码,例如模型定义、数据加载、训练循环等
cleanup()
- 在数据加载部分,需要确保数据能够正确地在多机之间分发。可以使用`torch.utils.data.distributed.DistributedSampler`。例如:python
from torch.utils.data.distributed import DistributedSampler
train_dataset = YourDataset()
train_sampler = DistributedSampler(train_dataset, num_replicas=world_size, rank=rank)
train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)
- 在模型同步方面,确保模型参数能够在不同机器的进程之间正确同步。例如,在每个训练步骤结束后,使用`dist.all_reduce`来同步梯度:python
for param in model.parameters():
dist.all_reduce(param.grad, op=dist.ReduceOp.SUM)
```
3. 多种解决方案的优缺点:
- 优点:
- 统一环境配置:确保所有机器环境一致,减少因环境差异导致的问题,提高代码的可重复性和稳定性。
- 网络配置完善:保证机器间通信正常,为分布式训练提供基础保障。
- 代码规范修改:按照分布式训练的标准流程修改代码,有助于正确实现多机多卡训练。
- 缺点:
- 环境配置繁琐:需要在多台机器上重复安装软件包,耗费时间和精力。
- 网络配置复杂:涉及局域网设置和防火墙配置,对于不熟悉网络的人员可能有一定难度。
- 代码修改量大:需要对原有的单机训练代码进行较多修改,可能引入新的错误。
4. 总结:
- 多机多卡训练yolo时出现问题,首先要确保环境、网络配置正确,然后按照分布式训练的规范修改代码。通过上述步骤,可以逐步排查和解决多机多卡训练过程中出现的通信、数据分发、模型同步等问题,实现稳定的分布式训练。
请注意,以上代码示例基于PyTorch,具体实现可能需要根据你的实际代码结构和需求进行调整。同时,不同的深度学习框架在分布式训练的实现上会有一些差异,需要参考相应的文档进行修改。
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。