
为什么运行voc_labels.py文件时候,存放YOLO文件夹的所有文件标注信息都被清空,且运行可以执行完毕就是在生成目录下main没有生成对应的2025_train.txt和 2025_val.txt.
这是文件目录Annotations是存xml文件,labels是存转换后的txt文件,:
这是目录下LimgeSets下main自定义train和val,其中train存了所有图片的文件名,val为空
这是labels下的
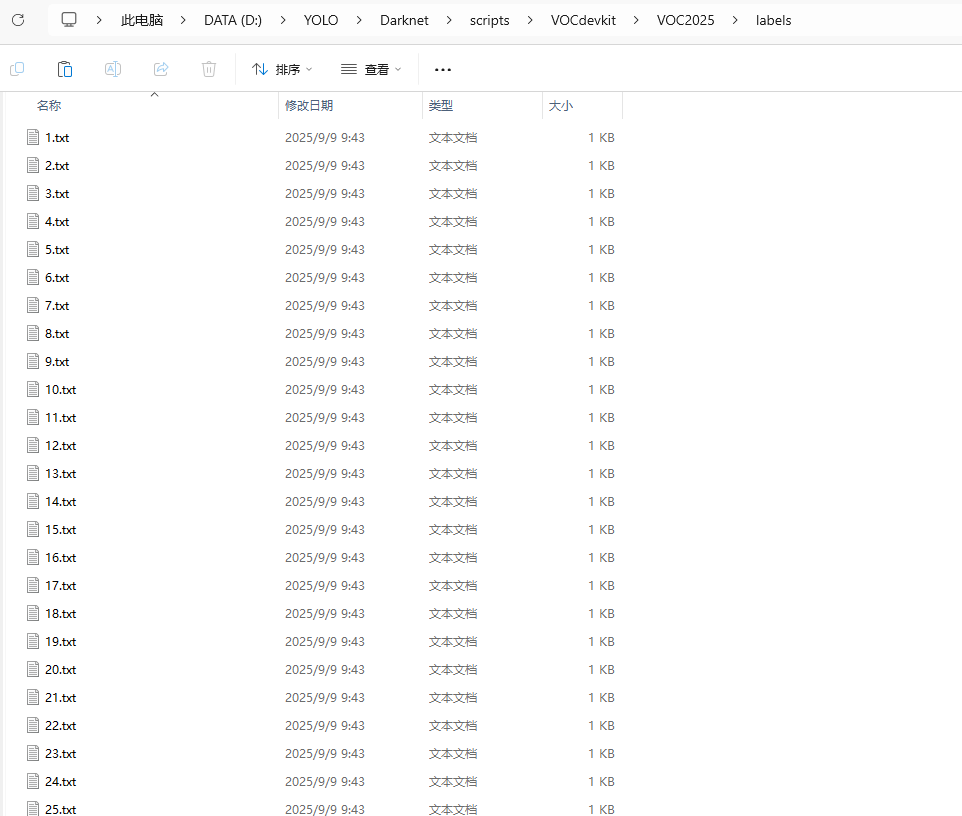
这是没有运行voc_labels.py文件时候labels中一个图片的YOLO信息
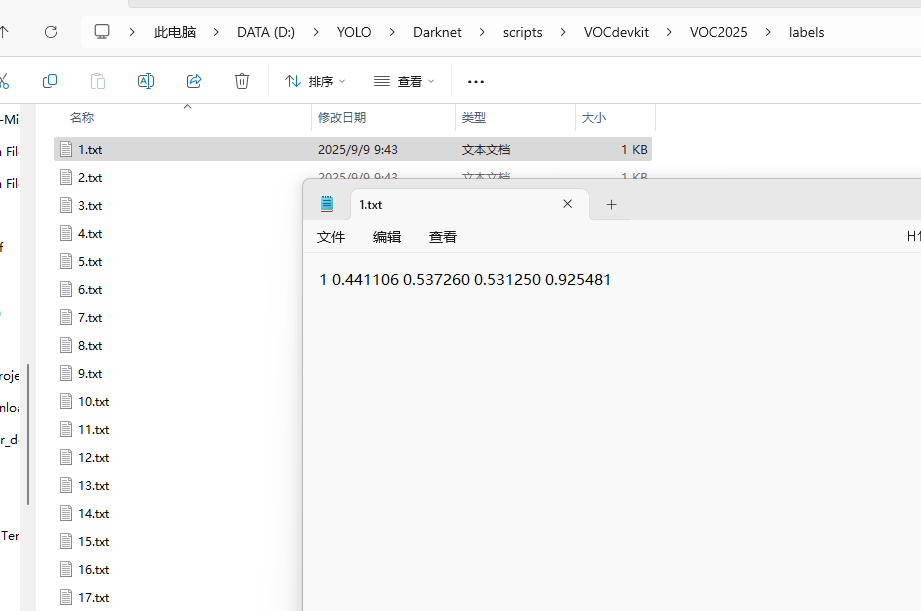
这是运行voc_labels.py文件时候labels中一个图片的YOLO信息都被清空了
这是voc_labels.py文件
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = [('2025', 'train'), ('2025', 'val')]
classes = ["shu"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open(f'D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC{year}\\Annotations\\{image_id}.xml')
out_file = open(f'D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC{year}\\labels\\{image_id}.txt', 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(f"{cls_id} {' '.join([str(a) for a in bb])}\n")
wd = getcwd()
for year, image_set in sets:
label_dir = f'D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC{year}\\labels\\'
if not os.path.exists(label_dir):
os.makedirs(label_dir)
image_ids = open(f'D:\\YOLO\\Darknet\\scripts\\VOCdevkit\\VOC{year}\\ImageSets\\Main\\{image_set}.txt').read().strip().split()
list_file = open(f'{year}_{image_set}.txt', 'w')
for image_id in image_ids:
list_file.write(f'D:\\YOLO\\Darknet\\build\\x64\\data\\obj\\{image_id}.jpg\n')
convert_annotation(year, image_id)
list_file.close()
# 合并 train 和 val 文件
try:
with open('train.txt', 'w') as f:
with open('2025_train.txt', 'r') as f1:
f.write(f1.read())
with open('2025_val.txt', 'r') as f2:
f.write(f2.read())
print("train.txt 已成功生成!")
except Exception as e:
print(f"生成 train.txt 失败: {e}")
#if os.access("file.txt", os.W_OK):
# print("You have write permission to the file.")
#else:
# print("You do not have write permission to the file.")
#print("train.txt 已成功生成!")







