关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
谷咕咕
2025-09-22 13:53
采纳率: 36.4%
浏览 10
首页
人工智能
已结题
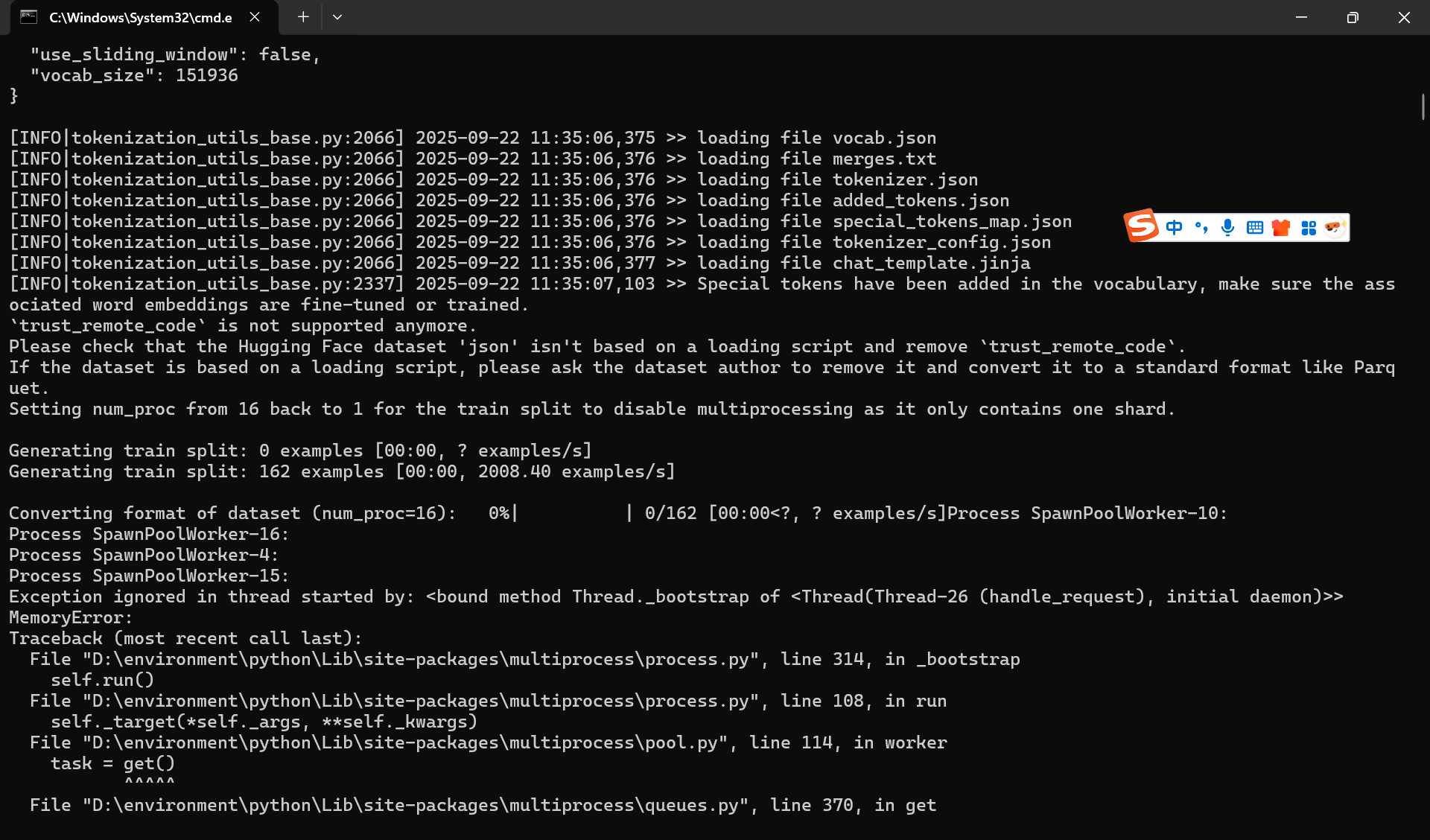
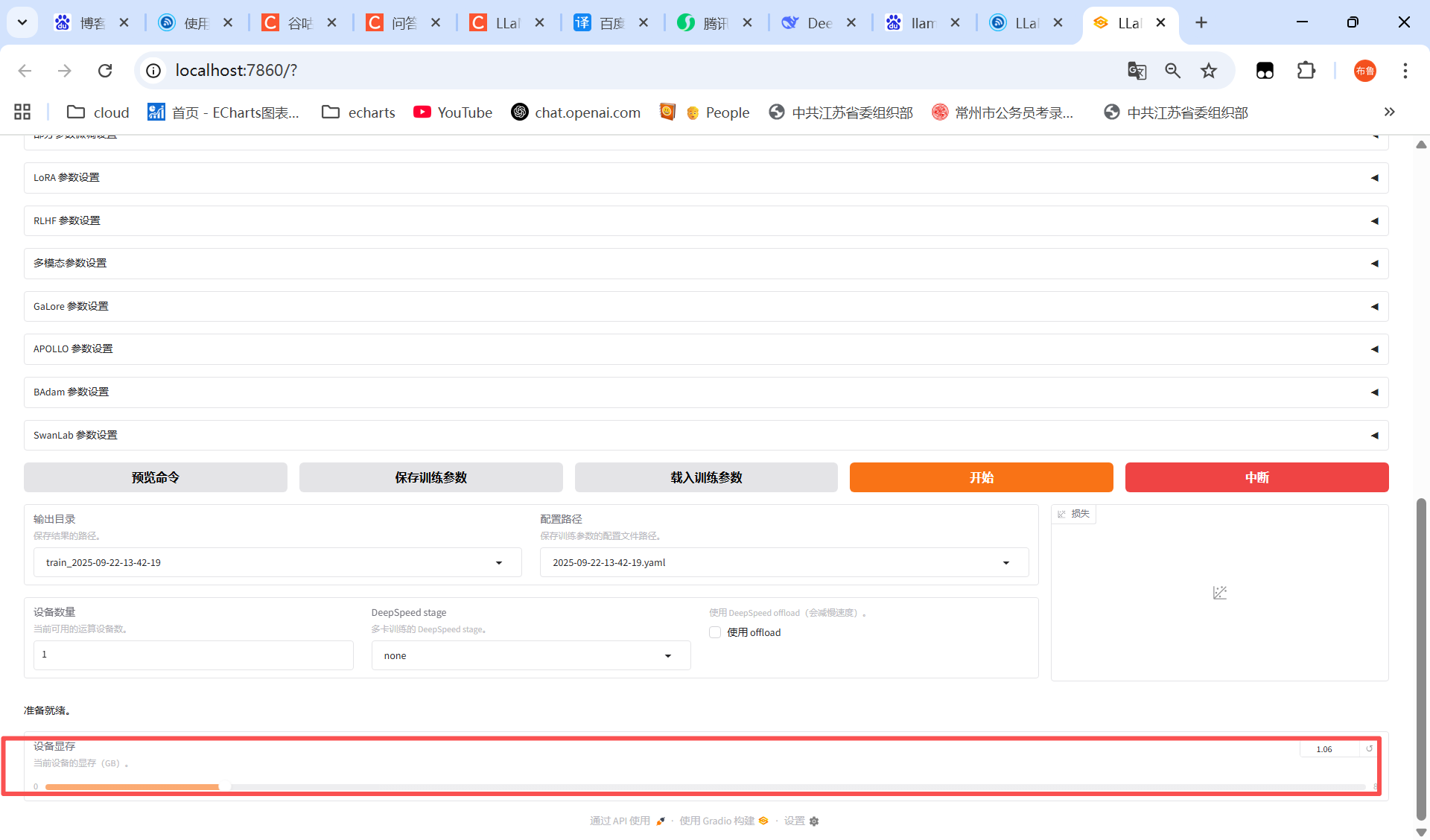
使用LLaMA-Factory微调的时候,提示这个是为什么, 是内存不足嘛,我8g的电脑默认只使用1.06g?
人工智能
使用LLaMA-Factory微调的时候,提示这个是为什么, 是内存不足嘛,我8g的电脑默认只使用1.06g?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
4
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
谷咕咕
全国人工智能系统部署与应用二等奖
2025-09-23 11:54
关注
已解决
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(3条)
向“C知道”追问
报告相同问题?
提交
关注问题
[NLP]
使用
Alpaca-Lora基于
llama
模型进行
微调
教程
2023-07-25 16:35
舒克与贝克的博客
Stanford Alpaca 是在
LLaMA
整个模型上
微调
,即对预训练模型中的所有参数都进行
微调
(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 ...
【国产异构加速卡】快速体验LoRA
微调
Llama
3-8B模型以及推理加速
2024-08-02 10:42
花花少年的博客
【国产异构加速卡】快速体验LoRA
微调
Llama
3-8B模型以及推理加速
训练细节揭秘:Qwen2.5-VL-7B-Cam-Motion-Preview的
微调
策略
2025-08-25 20:09
瞿蔚英Wynne的博客
训练细节揭秘:Qwen2.5-VL-7B-Cam-Motion-Preview的
微调
策略 【免费下载链接】qwen2.5-vl-7b-cam-motion-preview 项目地址: https://ai.gitcode.com...
【大模型理论篇】SWIFT: 可扩展轻量级的大模型
微调
基础设施
2025-04-08 23:58
源泉的小广场的博客
大模型、多模态、
微调
框架、训练框架、后处理框架、评估、多模态训练、swift、msswift
Llama
factory
如何全参数
微调
Qwen2.5-7B-Instruct 模型并导入O
llama
推理(详细版)
2025-04-26 14:55
玩人工智能的辣条哥的博客
Ubuntu20.04
Llama
factory
Qwen2.5-7B-Instruct
llama
.cppH20 95GX2
Llama
factory
如何全参数
微调
Qwen2.5-7B-Instruct 模型并导入O
llama
推理1. 全参数
微调
(Full Parameter Fine-tuning)全参数
微调
是指对预训练...
【Datawhaler AI夏令营-浪潮】大模型应用开发学习记录
2024-08-12 22:50
清尘丿的博客
简要:Datawhale 2024 年 AI 夏令营 第四期联合浪潮信息一同开展的学习活动。...首先搭个环境:步骤比较简单就是绑定魔搭后创建实例(这里开通绑定等图文步骤有其他学员也发出来了,实在不会搜搜)直接进入正题。
NeurIPS 2025 Spotlight | 甩掉文本CoT!FSDrive:自动驾驶VLA新范式
2025-10-11 10:50
CV炼丹术的博客
《FutureSightDrive:基于时空视觉链式思考的自动驾驶框架》提出了一种创新的自动驾驶视觉推理方法。该研究突破传统文本链式推理的局限,通过构建统一的图像形式时空CoT(时空链式思考...这种视觉思考范式为自动驾驶提
LLM大语言模型综述
2023-01-10 13:55
hit56笔记的博客
理解类任务的特点是,输入一个句子(文章),或者两个句子,模型最后判断属于哪个类别,所以本质上都是分类任务,比如文本分类、句子关系判断、情感倾向判断等。生成类任务的特点是,给定输入文本,对应地,模型要...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
10月1日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
9月23日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
9月22日

 分享
分享 系统已结题
10月1日
系统已结题
10月1日 已采纳回答
9月23日
创建了问题
9月22日
已采纳回答
9月23日
创建了问题
9月22日


