

问题遇到的现象和发生背景
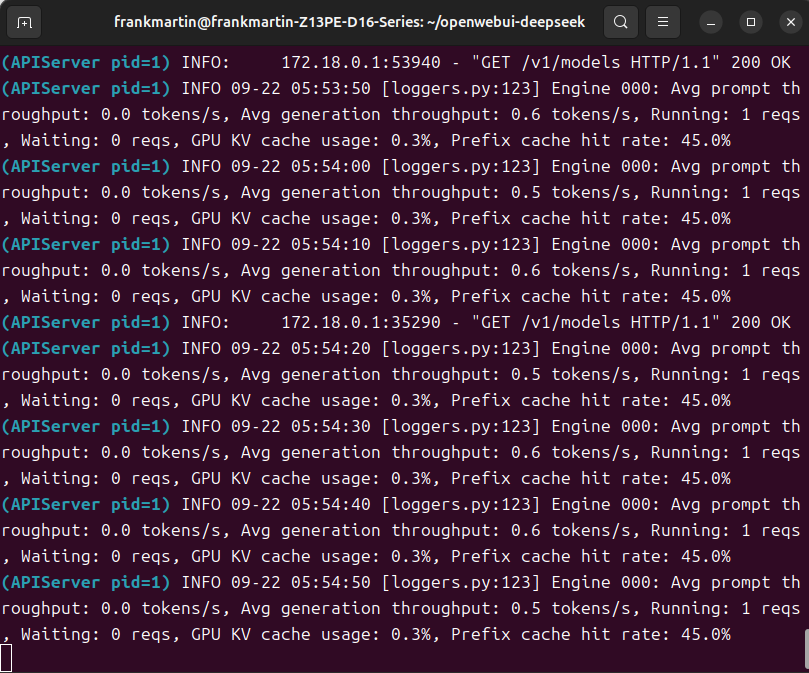
本地采用VLLM架构作后端,open-webui作前端部署大模型,下载了Qwen-235B-A22B-2507的模型(模型大小400G),VLLM后段日志显示每秒只有0.6-0.8 token,
操作环境、软件版本等信息
电脑配置英特尔6530 双路,1024GB DDR5 4800频率内存,显卡为一张RTX 5880 Ada,48G显存,我看很多朋友4070或者4080跑deepseek 671B Q4量化都能有10多tokens,我这个速度是不是不正常?
尝试过的解决方法
VLLM端显存限制 gpu-memory-utilization 为0.95,上下文限制为8192,因为显存不够,分配了480内存和48显存混合运算
我想要达到的结果
这个配置跑这个速度正常吗?








