
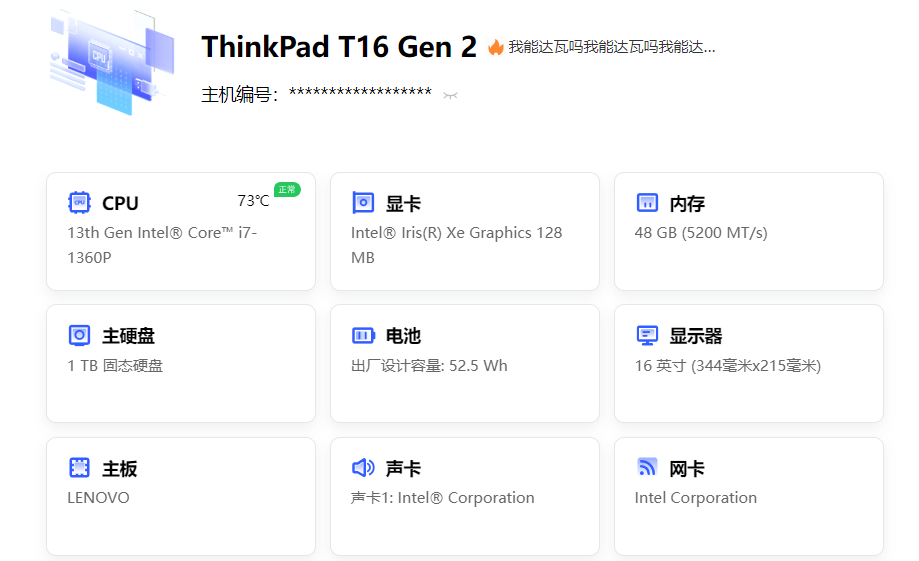
请问这样的配置适合部署哪种算力规模的AI呀?ds推荐14B~34B,想用来分析文本,有一定的推理能力,不知道这个范围内的AI能不能达到这样的水平呀(ds的措辞感觉有时候有些夸张),求解答🥹🥺

 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载预训练模型和分词器
model_name = "your_model_name" # 替换为具体的14B - 34B规模的模型名称
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 准备文本
text = "你的待分析文本"
# 对文本进行编码
inputs = tokenizer(text, return_tensors='pt')
# 进行推理
outputs = model(**inputs)
logits = outputs.logits
需要注意的是,具体的模型选择和实际性能还需要根据你实际的硬件配置、数据情况等进行进一步的测试和调整。
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 系统已结题
10月28日
系统已结题
10月28日 已采纳回答
10月20日
修改了问题
10月19日
创建了问题
10月19日
已采纳回答
10月20日
修改了问题
10月19日
创建了问题
10月19日

