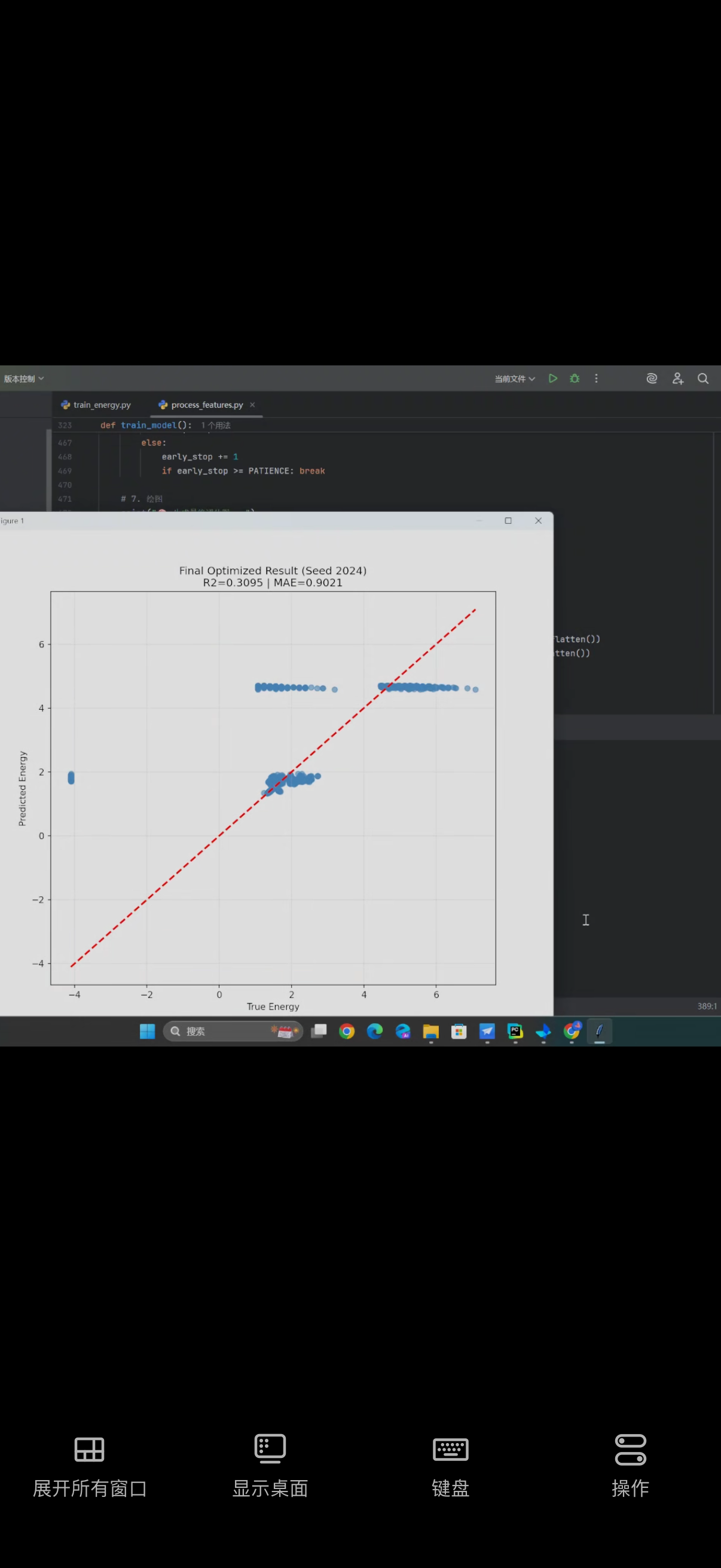
这个图片是利用GNN来构建关于富勒烯模型,数据库中数据的尾缀是xyz文件类型,这个模型是构建预测形成能的模型,前期效果是还不错的,但是每次预测完都会出现一条直线,请问一下是脚本出现问题了吗,有哪些地方可以进行改进呢

这个图片是利用GNN来构建关于富勒烯模型,数据库中数据的尾缀是xyz文件类型,这个模型是构建预测形成能的模型,前期效果是还不错的,但是每次预测完都会出现一条直线,请问一下是脚本出现问题了吗,有哪些地方可以进行改进呢
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
问题分析
根据你的描述,前期拟合效果不错,但是后面拟合效果变成一条直线,这通常是由于模型过拟合或欠拟合导致的。考虑到你使用的是GNN来构建富勒烯模型,并且数据是xyz文件类型,可能存在以下几种情况:
解决方案
核心代码
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import EarlyStopping
# 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 模型调整
model = RandomForestRegressor(n_estimators=100, random_state=42)
early_stopping = EarlyStopping(monitor='val_loss', patience=5, min_delta=0.001)
# 训练模型
model.fit(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping])
以上是核心代码部分,具体的实现细节需要根据你的具体情况进行调整。
分享 已结题
(查看结题原因) 4月7日
创建了问题
12月27日
已结题
(查看结题原因) 4月7日
创建了问题
12月27日
