
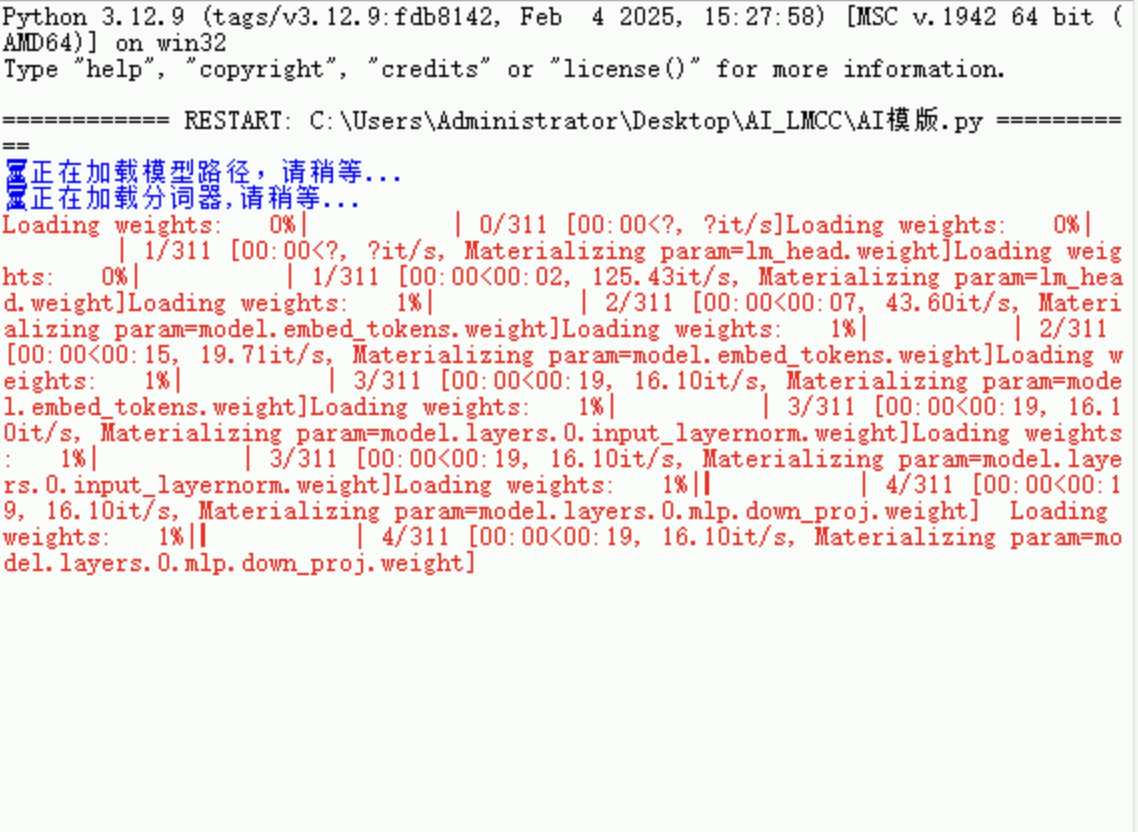
使用modelscope下载预训练模型(Qwen3-0.6B)在本地,然后再通过transformers和PyTorch加载该模型并进行后续训练, 在transformers加载模型过程中出现问题, 并且时间越来越久,请问怎么解决
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
print("⌛️检查模型路径...")
model_path = "./qwen3-0.6B/qwen/Qwen3-0___6B" #模型路径
print("✅模型路径检查完成!")
print("⌛️加载分词器...")
tokenizer=AutoTokenizer.from_pretrained(model_path,local_files_only=True)
print("✅分词器加载完成!")
print("⌛️正在加载模型...")







