正在学习一个情感分析的项目,但是搭建cpu下的transformer的环境时总是因为调取bert时超时,
按照机构改的强制本地离线加载还是不成功,能看看是哪里出的问题吗
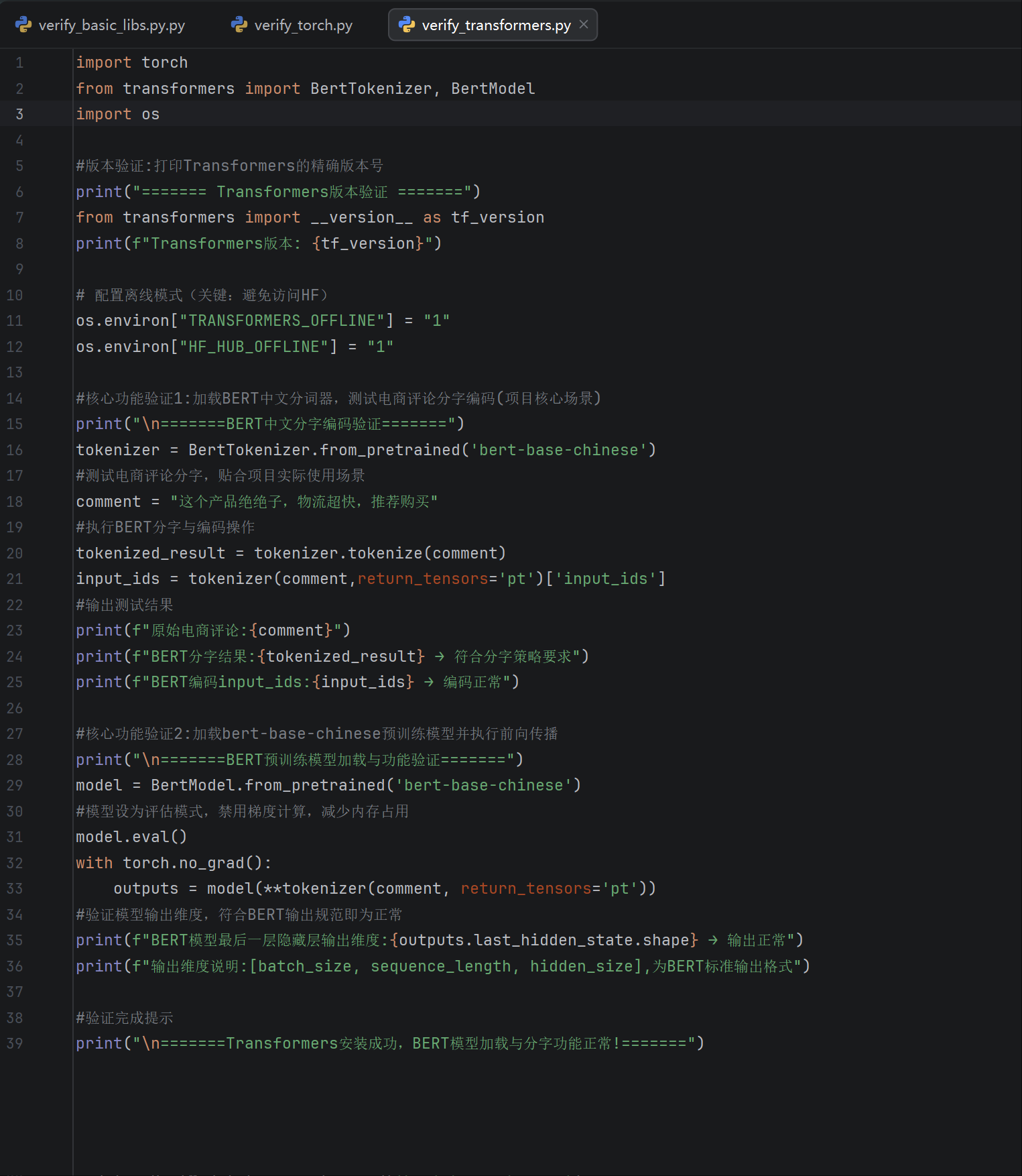
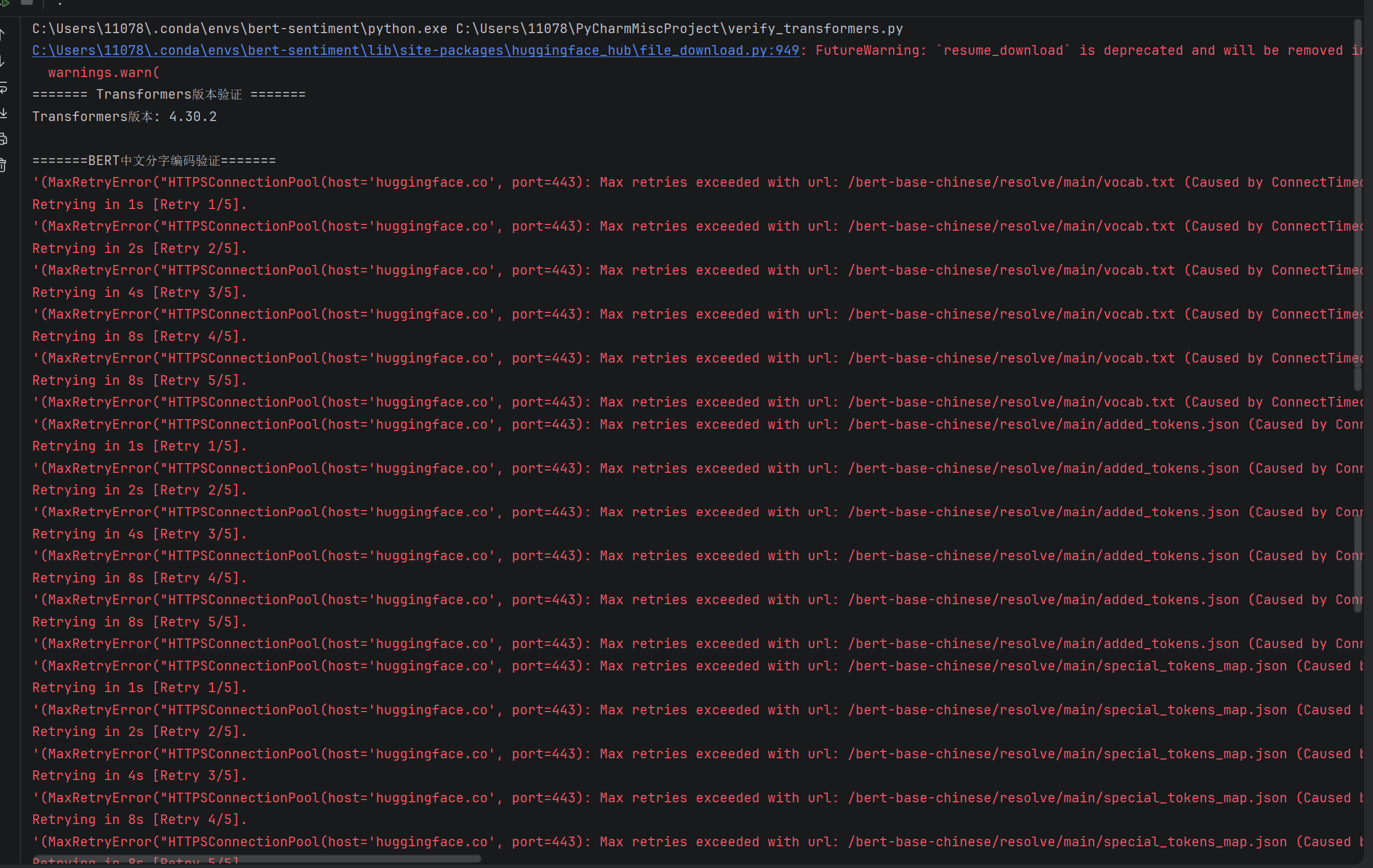


正在学习一个情感分析的项目,但是搭建cpu下的transformer的环境时总是因为调取bert时超时,
按照机构改的强制本地离线加载还是不成功,能看看是哪里出的问题吗
 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
在搭建 BERT 情感分析项目时,遇到 “调取 BERT 时超时” 或 “无法本地离线加载” 的问题,通常与以下几种原因有关:
网络连接不稳定或受限
bert-base-uncased)默认通过互联网下载,若你所在环境的网络被限制,或者防火墙/代理设置不正确,会导致下载超时。未正确配置本地缓存路径
使用了错误的模型名称或路径
依赖库版本不兼容
transformers 库版本过低,可能不支持某些功能或模型格式。缺少必要的依赖包
torch, tokenizers, sentencepiece 等,未正确安装也可能导致加载异常。你可以通过以下方式强制从本地加载 BERT 模型,避免联网请求:
from transformers import BertTokenizer, BertModel
# 指定本地模型路径(假设你已将模型文件放在 "local_bert_model/" 目录下)
model_path = "./local_bert_model/"
# 加载 tokenizer 和 model
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
重点:确保你已经将完整的 BERT 模型文件(如
config.json,pytorch_model.bin,vocab.txt等)放入指定的本地目录中。
如果你尚未下载模型,可以先在有网络的环境中下载模型,然后复制到本地。
pip install transformers
from transformers import BertTokenizer, BertModel
# 下载模型到本地
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased", cache_dir="./local_bert_model")
model = BertModel.from_pretrained("bert-base-uncased", cache_dir="./local_bert_model")
将 ./local_bert_model 文件夹打包,上传到无网络环境的机器上。
在无网络环境下,使用上述的本地路径加载模型。
你可以通过设置环境变量来强制 transformers 不进行联网下载:
export TRANSFORMERS_OFFLINE=1
注意:此方法仅适用于你已手动下载了所有需要的模型和依赖项的情况。
--local_files_only 参数如果你已经下载了模型文件,可以使用这个参数防止它尝试从远程下载:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 强制使用本地文件
tokenizer = AutoTokenizer.from_pretrained("./local_bert_model/", local_files_only=True)
model = AutoModelForSequenceClassification.from_pretrained("./local_bert_model/", local_files_only=True)
确保你安装的 transformers 和 torch 版本兼容:
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 --extra-index-url https://download.pytorch.org/whl/cu111
pip install transformers==4.6.0
建议:查看你使用的 BERT 模型是否兼容当前版本的
transformers。
from transformers import BertTokenizer, BertModel
# 本地模型路径
model_path = "./local_bert_model/"
# 加载 tokenizer 和 model
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
# 示例输入
text = "I love natural language processing!"
inputs = tokenizer(text, return_tensors="pt")
# 推理
outputs = model(**inputs)
print(outputs.last_hidden_state.shape) # 输出形状为 (1, seq_len, hidden_size)
config.json, pytorch_model.bin, vocab.txt 等)。venv 或 conda 创建独立环境,避免依赖冲突。| 问题类型 | 解决方案 |
|---------|----------|
| 网络超时 | 配置本地模型路径,关闭联网下载 |
| 本地加载失败 | 确保模型文件完整,路径正确 |
| 依赖不兼容 | 更新 transformers 和 torch 版本 |
| 环境配置错误 | 使用虚拟环境,避免依赖冲突 |
如有更多关于模型结构、训练流程或具体错误信息,欢迎继续提问!
分享 修改了问题
3月10日
创建了问题
3月10日
修改了问题
3月10日
创建了问题
3月10日


