离线环境,大模型能创建,能加载,各种版本软件也是最新的,但是一跑大模型搞么卡死,要么
就报500。,谢谢
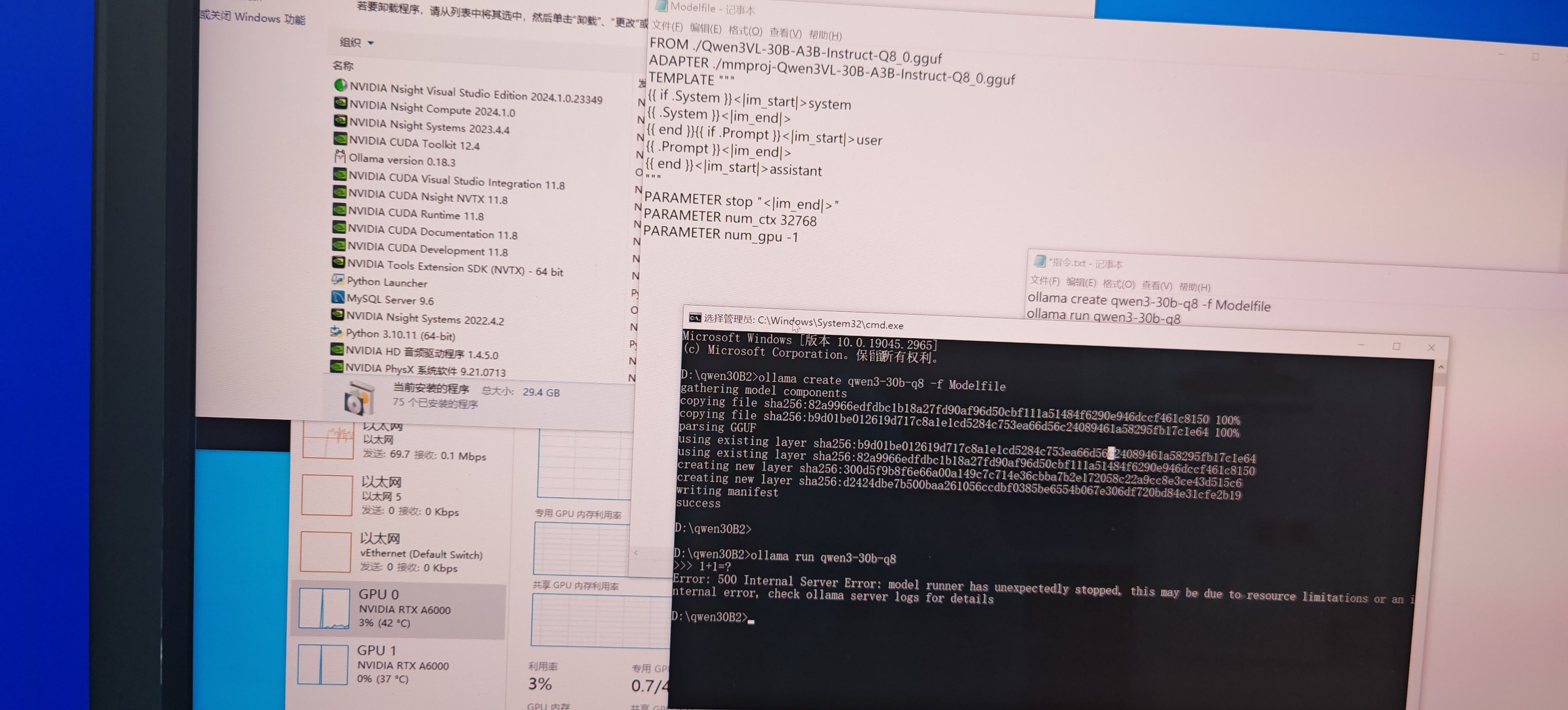
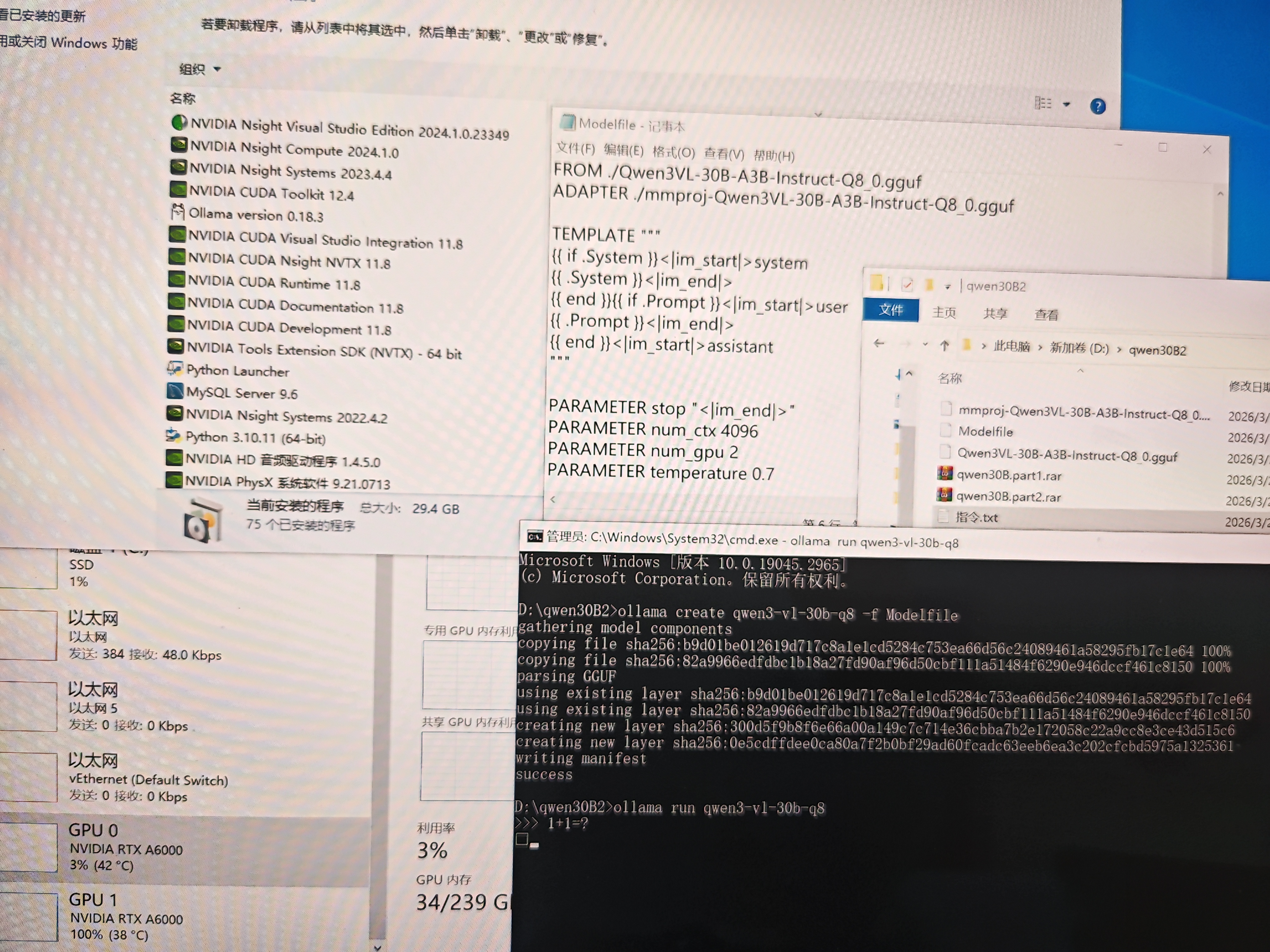

离线环境,大模型能创建,能加载,各种版本软件也是最新的,但是一跑大模型搞么卡死,要么
就报500。,谢谢
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
在离线环境中使用 Ollama 运行 Qwen-30B (Q8) 时,如果遇到 500 错误 或模型卡死的问题,可能是由多种因素引起的。以下是一些可能的原因和详细的解决方案:
config.json 或其他元数据文件损坏也可能导致 500 错误。GPU 显存:
nvidia-smi 查看显存是否足够。系统内存:
重点提示:
Qwen-30B 在 Q8 量化下仍需较大显存,建议使用 24GB 以上 GPU,否则无法正常运行。
.gguf 或 .bin)。示例模型目录结构:
qwen-30b-q8/
├── config.json
├── tokenizer.model
├── model.bin
└── model.gguf
修改后的命令示例:
# 卸载旧版本
sudo apt remove ollama
# 安装新版本
curl -fsSL https://ollama.com/install.sh | sh
/etc/ollama/config.json)。{
"model_max_length": 2048,
"gpu_layers": 100,
"max_batch_size": 1,
"log_level": "info"
}
重点提示:
gpu_layers应根据你的 GPU 显存进行合理设置,例如:
- 24GB 显存:
"gpu_layers": 50- 40GB 显存:
"gpu_layers": 100
ollama run qwen-30b-q8
ollama create qwen-30b-q8 --file /path/to/qwen-30b-q8/model.gguf
journalctl -u ollama
ollama serve
重点提示:
500 错误通常表示服务器内部错误,通过日志可以定位具体原因。
| 错误类型 | 可能原因 | 解决方法 | |----------|----------|----------| | 500 Internal Server Error | 显存不足、模型损坏、配置错误 | 增加显存、重新下载模型、检查配置 | | Model loading failed | 模型格式不支持、文件缺失 | 确认模型格式、检查文件完整性 | | CUDA out of memory | 显存不足 | 使用更小的模型、增加 GPU 显存 |
如果你没有足够的 GPU 显存,可以考虑以下替代方案:
llama.cpp 或 vLLM)如有更多具体错误日志,欢迎提供,我可以进一步帮助你分析!
分享 创建了问题
3月30日
创建了问题
3月30日


