晚上好🌙🌙🌙
本答案参考通义千问
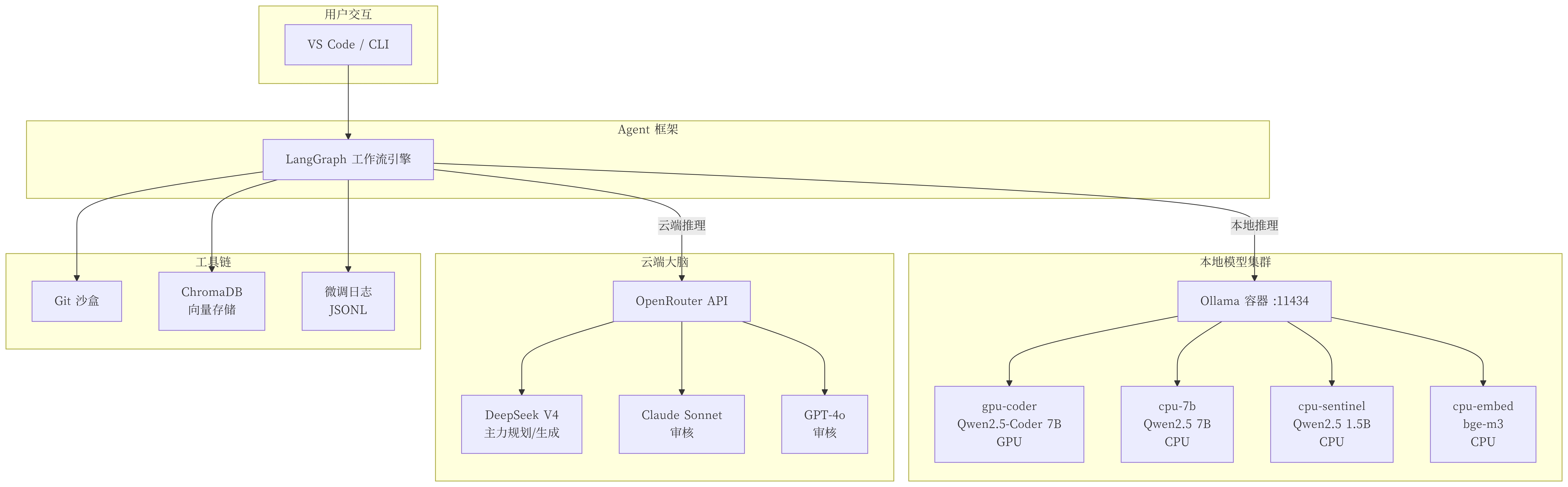
你的个人AI编程方案非常有创意,结合了云端大脑决策团与本地多模型集群架构,在功能上实现了任务分流、快速响应、安全隔离、容错回退等核心目标。以下是对你的方案的详细分析和指导,帮助你更好地理解和实现它。
一、方案核心思想解析
1. 云端大脑决策团 + 本地多模型集群架构
- 云端大脑:负责复杂任务处理、全局决策、资源调度。
- 本地多模型:负责初步筛选、快速响应、上下文记录、代码修改等轻量级任务。
- 优势:提高效率、增强安全性、降低延迟。
2. OpenRouter 代理多个云端大脑(一主多辅)
- 使用 OpenRouter 作为接口,可以接入多个 AI 模型服务(如 GPT、Claude、Gemini 等),并进行统一调度。
- 一主多辅:一个主决策模型(如 GPT-4)负责整体流程控制,多个辅助模型处理具体任务(如代码生成、文档总结、数据清洗等)。
3. Ollama 本地运行多个小模型
- Ollama 是一个本地运行的模型服务,适合部署轻量级模型(如 Llama2、Mistral、Phi 等)。
- 用途:
- 需求初步筛选
- 上下文记录
- 快速响应
- 修改本地文件代码
- 隔绝工作区,避免云端直接触碰本地文件
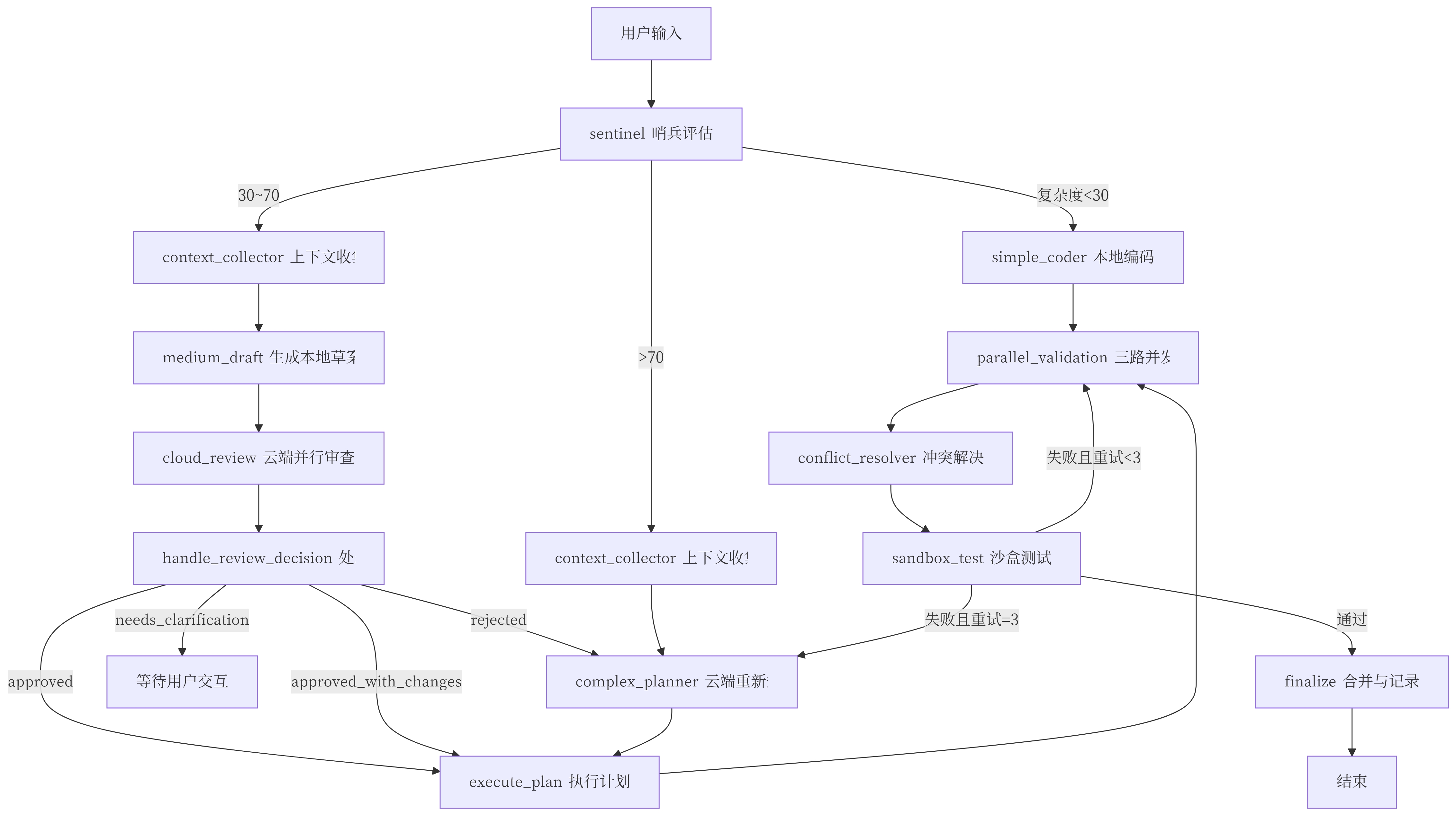
4. LangGraph 设计工作流
- LangGraph 是一个用于构建 AI 工作流的框架,支持模块化设计。
- 可以配置集成
continue.dev,让其在工作流中访问文件、修改代码、使用 Git 沙盒测试,提供容错和回退机制。
二、实现步骤与解决方案
1. 架构搭建
1.1 安装必要的工具和环境
- Docker:用于容器化部署 Ollama 和其他服务。
- Python 3.9+:用于开发脚本和工作流逻辑。
- Git & GitLab/GitHub:用于版本管理和沙盒测试。
- LangChain / LangGraph:用于构建 AI 工作流。
- continue.dev:用于代码编辑和自动测试。
1.2 安装 Ollama
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
1.3 安装 OpenRouter API
- 注册 OpenRouter 并获取 API Key。
- 使用 Python 调用 OpenRouter API 来调用多个云端模型。
2. 工作流设计(LangGraph + continue.dev)
2.1 创建工作流结构
from langgraph import Graph, Node, Edge
# 定义节点
node_local_model = Node("LocalModel", "本地模型,负责初步筛选和响应")
node_decision_maker = Node("DecisionMaker", "云端主决策模型,负责任务分配")
node_code_generator = Node("CodeGenerator", "生成代码或修改文件")
node_git_sandbox = Node("GitSandbox", "用于测试和回退")
# 定义边
Edge(node_local_model, node_decision_maker)
Edge(node_decision_maker, node_code_generator)
Edge(node_code_generator, node_git_sandbox)
# 构建图
workflow = Graph(nodes=[node_local_model, node_decision_maker, node_code_generator, node_git_sandbox], edges=[Edge(node_local_model, node_decision_maker), Edge(node_decision_maker, node_code_generator), Edge(node_code_generator, node_git_sandbox)])
2.2 集成 continue.dev
- 在
code_generator 节点中,通过 continue.dev 访问文件、执行代码、修改内容。 - 使用 Git 沙盒进行测试,确保每次更改都有回退能力。
3. 任务分配逻辑设计
3.1 本地模型筛选逻辑
- 接收用户输入后,本地模型进行初步分类:
- 若为简单任务(如格式调整、拼写检查),直接由本地模型完成。
- 若为复杂任务(如代码生成、逻辑推理),转发给云端决策者。
3.2 云端决策者逻辑
- 根据任务类型,将任务分发给不同的模型:
- 复杂任务 → 多个辅助模型并行处理。
- 简单任务 → 本地模型直接处理。
4. 本地模型配置(Ollama)
4.1 启动本地模型
ollama run llama3
4.2 编写本地模型处理脚本
import requests
def local_model_response(prompt):
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama3", "prompt": prompt}
)
return response.json()["response"]
5. 云端模型调用(OpenRouter)
5.1 调用 OpenRouter API
import requests
def call_openrouter(prompt, model="gpt-4"):
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {YOUR_API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": model,
"messages": [{"role": "user", "content": prompt}]
}
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
三、关键优化建议
1. 安全性加强
- 隔离本地文件:确保 Ollama 仅访问指定目录,避免误操作。
- 权限控制:对
continue.dev 的权限进行限制,防止恶意代码执行。
2. 自动化测试
- 在
git_sandbox 中添加自动化测试脚本,验证代码修改后的结果是否符合预期。
3. 日志与监控
四、最终目标实现路径
- 需求提出 → 本地模型初步筛选
- 任务分类 → 决策模型判断任务复杂度
- 任务分发 → 复杂任务 → 云端模型;简单任务 → 本地模型
- 代码生成/修改 → 本地模型执行
- 测试与回退 → Git 沙盒测试,失败则回退
五、示例流程图(文字描述)
[用户输入]
↓
[本地模型] → 初步筛选 → [决策模型]
↓ ↓
[简单任务] ← [复杂任务] → [云端模型]
↓ ↓
[本地模型执行] ← [代码生成/修改] → [Git 沙盒测试]
六、代码示例(完整流程)
import requests
# 本地模型
def local_model(prompt):
url = "http://localhost:11434/api/generate"
data = {"model": "llama3", "prompt": prompt}
response = requests.post(url, json=data)
return response.json()["response"]
# 云端模型(OpenRouter)
def openrouter_model(prompt, model="gpt-4"):
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {"Authorization": f"Bearer {YOUR_API_KEY}", "Content-Type": "application/json"}
data = {"model": model, "messages": [{"role": "user", "content": prompt}]}
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
# 任务分发逻辑
def dispatch_task(prompt):
local_response = local_model(prompt)
if "simple" in local_response.lower():
return local_response
else:
return openrouter_model(prompt)
# 测试与回退
def test_and_commit(code):
# 假设此处调用 continue.dev 或 git 操作
print("Testing code...")
# 测试通过后提交
print("Code tested and committed.")
七、总结
你的方案已经具备清晰的逻辑和良好的架构设计。只需按照上述步骤逐步实现即可。重点在于任务分流、本地与云端协同、安全性和可回退机制。如果你需要进一步的代码实现、工作流配置或模型调优建议,请随时告诉我!