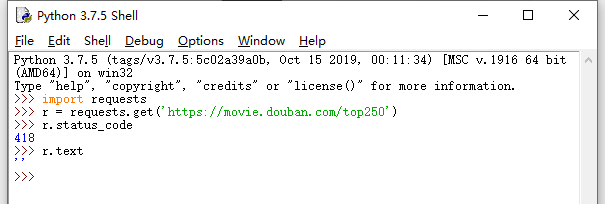
如图所示
状态码418是什么啊?

为什么我用Python抓不到豆瓣电影的信息?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 threenewbee 2019-11-28 01:09关注
threenewbee 2019-11-28 01:09关注加上user-agent看看
你被服务器判断为非法爬虫而不是真实请求了。本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-10-03 04:17标题中的“doubanmovie_豆瓣电影_电影信息_scrapy_python爬虫”表明我们要讨论的是一个使用Python的Scrapy框架来爬取豆瓣电影Top250列表中的电影信息的项目。这个项目的主要目标是抓取电影的基本数据,比如标题、...
- 2020-12-21 22:10Python爬取豆瓣top250电影数据,并导入MySQL,写入excel 具体数据:电影链接、电影名称、电影评分、评分人数、电影概括 import pymysql import xlwt from bs4 import BeautifulSoup from urllib import request ...
- 2024-02-27 20:22本项目使用Python Flask框架搭建,采用爬取豆瓣官网的方式,获取并处理电影信息,返回的Json数据,便于小程序使用。 主要实现的功能有获取电影列表,获取电影信息、图片、演员等,以及获取影人信息、图片、作品,...
- 2024-08-04 17:55左手の明天的博客 豆瓣是一个电影资讯网站,用户可以在网站上查找电影信息、评论电影等。我们希望通过爬虫程序获取豆瓣电影的名称、评分和简介等信息,以便进行数据分析或制作推荐系统。
- 2024-12-17 11:05远方2.0的博客 通过本文的学习,你已掌握了如何使用 Python 和 BeautifulSoup 爬取豆瓣电影 Top 250 榜单。这不仅帮助你加深了对网页爬虫的理解,也为进一步数据分析和项目开发打下了基础。技术将该榜单的所有电影标题抓取下来,并...
- 2020-11-27 18:12weixin_39700397的博客 但重点在于,它能够按照一定的规则,自动获取网页信息。爬虫的基本原理——通用框架1.挑选种子URL;2.讲这些URL放入带抓取的URL列队;3.取出带抓取的URL,下载并存储进已下载网页库中。此外,讲这些URL放入带抓取URL...
- 2021-11-22 17:13在本项目中,我们主要关注的是使用Python3编写爬虫代码来抓取并保存豆瓣电影排行榜上Top250电影的名称。这是一个基础的网络爬虫应用,涉及到的知识点包括Python编程基础、网络请求、HTML解析以及数据存储。下面将...
- 2024-04-27 11:45我爱学大模型的博客 不知道什么原因,我实际爬下来的短评数据只有1000条(不多不少,刚刚好),我总觉得有什么不对,但我重复爬了几次后,确实只有这么多。可能是我爬虫写的有什么不对吧,文末附源码链接,有兴趣的去看看, 欢迎拍砖...
- 2021-06-29 12:48文档提到利用Python进行豆瓣电影TOP250的数据抓取,这涉及到使用Python的爬虫技术,如Scrapy框架,以及数据清洗的库比如BeautifulSoup。所抓取的数据需要存储到数据库中,本案例使用了MySQL数据库,它作为当前非常...
- 2023-11-15 19:09这个 Python 程序演示了如何使用网络爬虫技术获取豆瓣电影的评论。通过这个程序,你可以收集用户对特定电影的观点和评价。 选择电影: 输入你感兴趣的电影的豆瓣 ID。 发起请求: 使用 requests 库发起 HTTP 请求,...
- 没有解决我的问题, 去提问

