
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/gncj/170427.html']
def parse(self, response):
re_selector = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/h1")
title = response.xpath('//div[@class="article-head"]/h1/text()').extract()
create_time = response.xpath("//div[@class='article-detail bgc-fff']/div[1]/div/div/span/text()").extract()[0]
read_num = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]/text()").extract()
read_num无法提取数据
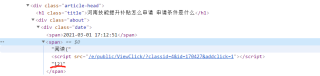
我通过xpath只能提取到")",这是为啥?请教!!!!







