
在爬取知网论文的关键词时,使用了以下代码:
for k in soup.find('p', attrs={"class":"keywords"}).find_all('a', target='_blank'):
keywords += (k.get_text())
网页关键词部分代码如下:
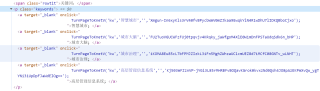
倒是没发生错误,但是导出后发现爬取的关键词只有一个,其它的并没有显示,这是怎么回事呀?各位大佬可以帮帮我吗?先谢谢大家啦!

在爬取知网论文的关键词时,使用了以下代码:
for k in soup.find('p', attrs={"class":"keywords"}).find_all('a', target='_blank'):
keywords += (k.get_text())
网页关键词部分代码如下:
倒是没发生错误,但是导出后发现爬取的关键词只有一个,其它的并没有显示,这是怎么回事呀?各位大佬可以帮帮我吗?先谢谢大家啦!
 分享
分享
可以参考这篇文章,希望对你有帮助:Python爬虫根据关键词爬取知网论文摘要并保存到数据库中【入门必学】 - 程序员的人生A - 博客园 (cnblogs.com)
分享



