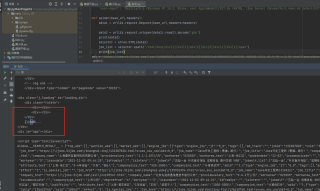
你这个网页中的内容是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
用requests只是获取网页的静态源代码。不会执行页面中的js代码,你用time.sleep()等待是没有用的。
只有用selenium 打开真正的浏览器。 才会执行页面中的js代码,用time.sleep()等待才有用。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
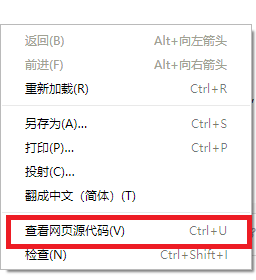
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
你题目的解答代码如下:
from selenium import webdriver
from lxml import etree
import time
def spider(base_url):
driver = webdriver.Chrome()
driver.get(base_url)
time.sleep(5)
data2 = driver.page_source
print(data2)
selector = etree.HTML(data2)
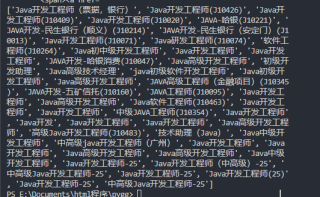
job_list = selector.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[1]/span[1]/text()")
print(job_list)
url = "https://search.51job.com/list/010000%252c020000%252c030200%252c040000%252c080200,000000,0121,01,9,99,+,2,99.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
spider(url)
如有帮助,望采纳!谢谢!