
现有命名实体识别任务,想使用bilstm+crf训练,打算将NER模型解耦,分解为encoder和tagger,encoder负责文本特征变换,使用bilstm,tagger负责序列标注,使用crf,但是在使用bilstm前发现需要先进行embedding,

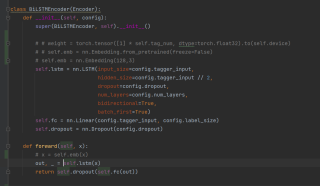
此为bilstm模型部分
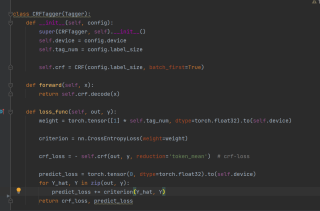
此为crf模型部分
import torch
from transformers import BertTokenizer
class Config:
def __init__(self):
super(Config, self).__init__()
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.bert_name = 'bert-base-cased'
self.bert_path = 'emb'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_name, cache_dir=self.bert_path)
self.pad_size = 128
self.dropout = 0.5
self.num_layers = 2
self.batch_size = 16
self.epoch_size = 1
self.learning_rate = 2e-5
self.weight_decay = 1e-4
self.label2idx = dict()
with open('data/label.txt', 'r', encoding='utf8') as file:
tags = file.read().split('\n')
for idx, t in enumerate(tags):
if t:
self.label2idx[t] = idx
self.label_size = len(self.label2idx)
self.tagger_input = 768
config = Config()
此为config.py
下为入口主函数文件
import torch
import random
import numpy as np
from config import config
from torch.utils.data import DataLoader
from util.dataTool import NERDataset
from util.model import BertModelEncoder, BiLSTMEncoder, BertBiLSTMEncoder, CRFTagger, SoftmaxTagger, NERModel
from util.trainer import train, test
from multiprocessing import cpu_count
# seed everything
# 设置随机数,保证相同环境下实验结果可复现
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
if __name__ == '__main__':
# 通过数据接口加载数据集并进行预处理
print("Data Loading...")
train_set = NERDataset('data/eng.train', config)
test_set = NERDataset('data/eng.testa', config)
val_set = NERDataset('data/eng.testb', config)
# 计算CPU核心数量,设置为num_workers
cpu_num = cpu_count()
# 训练时使用DataLoader,方便获取mini-batch
# batch_size:每次梯度更新使用的样本数量
# drop_last:按照指定batch分割数据时,存在余数。训练时drop,测试时保留
# shuffle:打乱数据集
# pin_memory:将数据从CPU加载到GPU时,为该loader分配固定的显存,提高IO效率
# num_workers:将数据加载到GPU的线程数量,合适的线程数量可以提高IO效率,从而提高GPU利用率
train_loader = DataLoader(train_set, batch_size=config.batch_size,
drop_last=True, shuffle=True, pin_memory=True, num_workers=cpu_num)
test_loader = DataLoader(test_set, batch_size=config.batch_size,
drop_last=False, shuffle=True, pin_memory=True, num_workers=cpu_num)
val_loader = DataLoader(val_set, batch_size=config.batch_size,
drop_last=False, shuffle=True, pin_memory=True, num_workers=cpu_num)
# encoder和tagger的初始化
print("Model Loading...")
# encoder = BertModelEncoder(config)
encoder = BiLSTMEncoder(config)
# encoder = BertBiLSTMEncoder(config)
tagger = CRFTagger(config)
# tagger = SoftmaxTagger(config)
# 组装NER模型
model = NERModel(encoder, tagger).to(config.device)
# 设置优化器,常见的有SGD、Adam、RMSprop等
optimizer = torch.optim.AdamW(params=model.parameters(),
lr=config.learning_rate, weight_decay=config.weight_decay)
# 通过训练接口训练模型
print("Training")
model = train(model, train_loader, val_loader, optimizer, config)
# 测试
test(model, test_loader, config)
请赐教,不胜感激。
具体代码可见仓库https://gitee.com/xin-yue-qin/resume-ner








