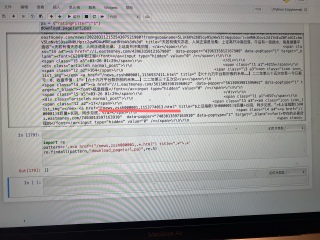
我想要抓取网页中所有评论,如红线标注所示,利用了正则表达式,但显示不出结果,这应该怎么修改呢

我想要抓取网页中所有评论,如红线标注所示,利用了正则表达式,但显示不出结果,这应该怎么修改呢
 分享
分享
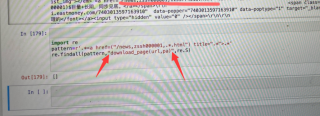
直接找字符串 download_page(url,pa) 肯定没内容了,应该是找download_page函数返回值,去掉前后的双引号

分享 系统已结题
4月3日
系统已结题
4月3日 已采纳回答
3月26日
创建了问题
3月26日
已采纳回答
3月26日
创建了问题
3月26日




