问题遇到的现象和发生背景
我有两个文件,一个是C.tsv。以下是部分数据
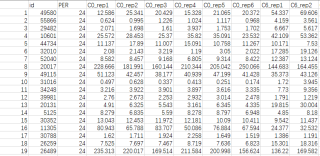
一个是文件: E.tsv。以下是部分数据
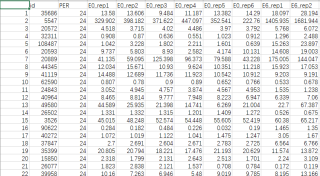
我想通过,C文件中的id那一列,找到E文件中也含有C中的id 的数据。然后输出E的整行数据。
说白了,就是找到C文件和E文件中的共有的id的整行的文件。
可以用Linux 也可以 用R。
请问大家有什么方法吗?

我有两个文件,一个是C.tsv。以下是部分数据
一个是文件: E.tsv。以下是部分数据
我想通过,C文件中的id那一列,找到E文件中也含有C中的id 的数据。然后输出E的整行数据。
说白了,就是找到C文件和E文件中的共有的id的整行的文件。
可以用Linux 也可以 用R。
请问大家有什么方法吗?
 分享
分享
在R中使用subset函数选取,代码:
d1<-read.csv('C.tsv',header=T,sep=' ')
d2<-read.csv('E.tsv',header=T,sep=' ')
res<-subset(d2,d2$id %in% d1$id)
print(res)
如有帮助,请点采纳按钮~~
分享 系统已结题
4月14日
系统已结题
4月14日 已采纳回答
4月6日
创建了问题
4月4日
已采纳回答
4月6日
创建了问题
4月4日



