想要爬取164页每页10条新闻,并把爬取到的信息存到exel文档。
一开始没补充getdata方法中的内容,只打印datalist可以输出
问题相关代码
from bs4 import BeautifulSoup #网页解析,获取数据
import urllib.request,urllib.error
import re
import xlwt
def main():
baseurl="https://www.dailynews.lk/search/node/China%20%20COVID-19?page=0"
datalist=getData(baseurl)
savepath="BBC中国疫情.xls"
saveData(datalist,savepath)
#askURL("https://www.dailynews.lk/search/node/China%20%20COVID-19?page=")
getData()
#新闻详情链接的规则
findLink=re.compile(r'<a href="(.*?)">')#创建正则表达式对象,表示规则(字符串的模式)r表示忽视特殊符号
#新闻时间
findDate=re.compile(r'<p class="search-info"><span about="/users/.*" class="username" datatype="" property="foaf:name" typeof="sioc:UserAccount" xml:lang="">.*</span> - (.*?) - .*</p>')
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,164):
url=baseurl+str(i*10)
html=askURL(url)#保存获取的网页源码
#逐一解析
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all("li",class_="search-result"): #查找符合要求的字符串,形成列表
#print(item)
data=[]#保存一条新闻的信息
item= str(item)
#获取新闻详情链接
link=re.findall(findLink,item)[0]
data.append(link)
#新闻日期
date=re.findall(findDate,item)[0]
date=re.sub('-',' ',date) #替换“-”
data.append(date)
datalist.append(data) #把信息放入datalist
return datalist
#得到指定url的网页内容
def askURL(url):
#模拟头部信息
head={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.46"}
#用户代理(告诉浏览器可以接受什么水平的文件内容)
request=urllib.request.Request(url,headers=head)
html=""
try:
respose=urllib.request.urlopen(request)
html=respose.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#保存数据
def saveData(datalist,savepath):
news = xlwt.Workbook(encoding="utf-8") # 创建book对象
sheet = news.add_sheet('BBC中国疫情') # 创建工作表
col = ("新闻详情链接", "新闻发布日期")
for i in range(0, 2):
sheet.write(0, i, col[i]) # 列名
for i in range(0, 1640):
print("第%d条" % i)
data = datalist[i]
for j in range(0, 2):
sheet.write(i + 1, j, data[j])
news.save(savepath) # save
if __name__ == '__main__':
main()
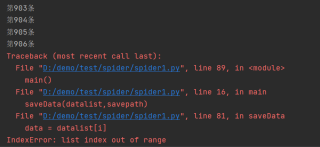
运行结果及报错内容
结果没有exel文档生成