问题遇到的现象和发生背景
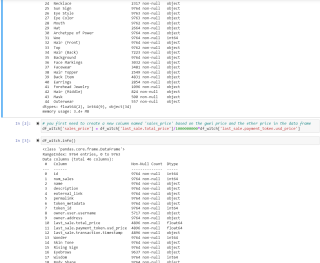
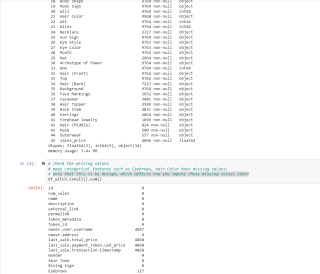
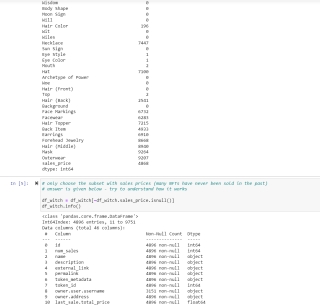
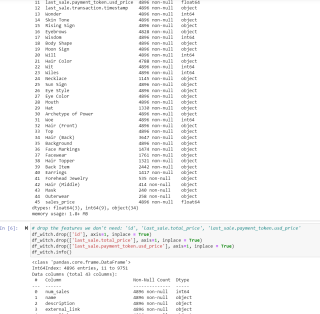
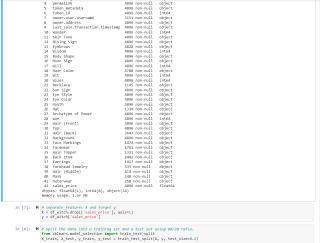
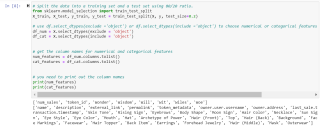
题目要求只为categorical features建立preprocessing pipelines
使用 'NA' 字符串计算缺失值:SimpleImputer(missing_values='NA', strategy='constant')
进行一次热编码并忽略未知值: OneHotEncoder(handle_unknown='ignore')
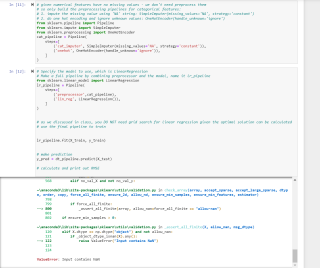
指定要使用的模型,即 LinearRegression
通过preprocessor和模型来制作一个full pipeline,将其命名为 lr_pipeline
使用final pipeline去train,不能用grid search
问题相关代码,请勿粘贴截图
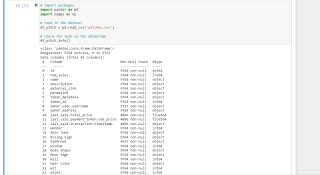
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
cat_pipeline = Pipeline(
steps=[
('cat_imputer', SimpleImputer(missing_values='NA', strategy='constant')),
('onehot', OneHotEncoder(handle_unknown='ignore')),
]
)
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('cat_pipeline', cat_pipeline, cat_features), # pipeline name, pipeline, features to process
]
)
from sklearn.linear_model import LinearRegression
lr_pipeline = Pipeline(
steps=[
('preprocessor',preprocessor),
('lin_reg', LinearRegression()),
]
)
lr_pipeline.fit(X_train, y_train)
运行结果及报错内容
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_9808/2178406682.py in
19 # use the final pipeline to train
20
-> 21 lr_pipeline.fit(X_train, y_train)
22
23
~\anaconda3\lib\site-packages\sklearn\pipeline.py in fit(self, X, y, **fit_params)
388
389 fit_params_steps = self._check_fit_params(**fit_params)
-> 390 Xt = self._fit(X, y, **fit_params_steps)
391 with _print_elapsed_time("Pipeline", self._log_message(len(self.steps) - 1)):
392 if self._final_estimator != "passthrough":
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _fit(self, X, y, **fit_params_steps)
346 cloned_transformer = clone(transformer)
347 # Fit or load from cache the current transformer
--> 348 X, fitted_transformer = fit_transform_one_cached(
349 cloned_transformer,
350 X,
~\anaconda3\lib\site-packages\joblib\memory.py in call(self, *args, **kwargs)
347
348 def call(self, *args, **kwargs):
--> 349 return self.func(*args, **kwargs)
350
351 def call_and_shelve(self, *args, **kwargs):
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _fit_transform_one(transformer, X, y, weight, message_clsname, message, **fit_params)
891 with _print_elapsed_time(message_clsname, message):
892 if hasattr(transformer, "fit_transform"):
--> 893 res = transformer.fit_transform(X, y, **fit_params)
894 else:
895 res = transformer.fit(X, y, **fit_params).transform(X)
~\anaconda3\lib\site-packages\sklearn\compose_column_transformer.py in fit_transform(self, X, y)
673 self._validate_remainder(X)
674
--> 675 result = self._fit_transform(X, y, _fit_transform_one)
676
677 if not result:
~\anaconda3\lib\site-packages\sklearn\compose_column_transformer.py in _fit_transform(self, X, y, func, fitted, column_as_strings)
604 )
605 try:
--> 606 return Parallel(n_jobs=self.n_jobs)(
607 delayed(func)(
608 transformer=clone(trans) if not fitted else trans,
~\anaconda3\lib\site-packages\joblib\parallel.py in call(self, iterable)
1041 # remaining jobs.
1042 self._iterating = False
-> 1043 if self.dispatch_one_batch(iterator):
1044 self._iterating = self._original_iterator is not None
1045
~\anaconda3\lib\site-packages\joblib\parallel.py in dispatch_one_batch(self, iterator)
859 return False
860 else:
--> 861 self._dispatch(tasks)
862 return True
863
~\anaconda3\lib\site-packages\joblib\parallel.py in _dispatch(self, batch)
777 with self._lock:
778 job_idx = len(self._jobs)
--> 779 job = self._backend.apply_async(batch, callback=cb)
780 # A job can complete so quickly than its callback is
781 # called before we get here, causing self._jobs to
~\anaconda3\lib\site-packages\joblib_parallel_backends.py in apply_async(self, func, callback)
206 def apply_async(self, func, callback=None):
207 "Schedule a func to be run"
--> 208 result = ImmediateResult(func)
209 if callback:
210 callback(result)
~\anaconda3\lib\site-packages\joblib_parallel_backends.py in init(self, batch)
570 # Don't delay the application, to avoid keeping the input
571 # arguments in memory
--> 572 self.results = batch()
573
574 def get(self):
~\anaconda3\lib\site-packages\joblib\parallel.py in call(self)
260 # change the default number of processes to -1
261 with parallel_backend(self._backend, n_jobs=self._n_jobs):
--> 262 return [func(*args, **kwargs)
263 for func, args, kwargs in self.items]
264
~\anaconda3\lib\site-packages\joblib\parallel.py in (.0)
260 # change the default number of processes to -1
261 with parallel_backend(self._backend, n_jobs=self._n_jobs):
--> 262 return [func(*args, **kwargs)
263 for func, args, kwargs in self.items]
264
~\anaconda3\lib\site-packages\sklearn\utils\fixes.py in call(self, *args, **kwargs)
214 def call(self, *args, **kwargs):
215 with config_context(**self.config):
--> 216 return self.function(*args, **kwargs)
217
218
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _fit_transform_one(transformer, X, y, weight, message_clsname, message, **fit_params)
891 with _print_elapsed_time(message_clsname, message):
892 if hasattr(transformer, "fit_transform"):
--> 893 res = transformer.fit_transform(X, y, **fit_params)
894 else:
895 res = transformer.fit(X, y, **fit_params).transform(X)
~\anaconda3\lib\site-packages\sklearn\pipeline.py in fit_transform(self, X, y, **fit_params)
424 "
425 fit_params_steps = self._check_fit_params(**fit_params)
--> 426 Xt = self._fit(X, y, **fit_params_steps)
427
428 last_step = self._final_estimator
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _fit(self, X, y, **fit_params_steps)
346 cloned_transformer = clone(transformer)
347 # Fit or load from cache the current transformer
--> 348 X, fitted_transformer = fit_transform_one_cached(
349 cloned_transformer,
350 X,
~\anaconda3\lib\site-packages\joblib\memory.py in call(self, *args, **kwargs)
347
348 def call(self, *args, **kwargs):
--> 349 return self.func(*args, **kwargs)
350
351 def call_and_shelve(self, *args, **kwargs):
~\anaconda3\lib\site-packages\sklearn\pipeline.py in _fit_transform_one(transformer, X, y, weight, message_clsname, message, **fit_params)
891 with _print_elapsed_time(message_clsname, message):
892 if hasattr(transformer, "fit_transform"):
--> 893 res = transformer.fit_transform(X, y, **fit_params)
894 else:
895 res = transformer.fit(X, y, **fit_params).transform(X)
~\anaconda3\lib\site-packages\sklearn\base.py in fit_transform(self, X, y, **fit_params)
853 else:
854 # fit method of arity 2 (supervised transformation)
--> 855 return self.fit(X, y, **fit_params).transform(X)
856
857
~\anaconda3\lib\site-packages\sklearn\impute_base.py in fit(self, X, y)
317 Fitted estimator.
318 "
--> 319 X = self._validate_input(X, in_fit=True)
320
321 # default fill_value is 0 for numerical input and "missing_value"
~\anaconda3\lib\site-packages\sklearn\impute_base.py in _validate_input(self, X, in_fit)
285 raise new_ve from None
286 else:
--> 287 raise ve
288
289 _check_inputs_dtype(X, self.missing_values)
~\anaconda3\lib\site-packages\sklearn\impute_base.py in _validate_input(self, X, in_fit)
268
269 try:
--> 270 X = self._validate_data(
271 X,
272 reset=in_fit,
~\anaconda3\lib\site-packages\sklearn\base.py in _validate_data(self, X, y, reset, validate_separately, **check_params)
564 raise ValueError("Validation should be done on X, y or both.")
565 elif not no_val_X and no_val_y:
--> 566 X = check_array(X, **check_params)
567 out = X
568 elif no_val_X and not no_val_y:
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
798
799 if force_all_finite:
--> 800 _assert_all_finite(array, allow_nan=force_all_finite == "allow-nan")
801
802 if ensure_min_samples > 0:
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in _assert_all_finite(X, allow_nan, msg_dtype)
120 elif X.dtype == np.dtype("object") and not allow_nan:
121 if _object_dtype_isnan(X).any():
--> 122 raise ValueError("Input contains NaN")
123
124
ValueError: Input contains NaN
我的解答思路和尝试过的方法