
问题遇到的现象和发生背景
selenium爬取网站数据,通过识别”id“获取text,由于页面较长,页面数据没有完全显示,结果只有显示的数据爬取的到,未显示的值爬取不到,如何解决?
问题相关代码,请勿粘贴截图
def downloaddata(num):
landdata = {}
lablename = {"地块名称":"dkmc", "四至范围":"szfw", "出让人":"crr", "出让方式":"crfs", "所属区县":"ssqx", "土地用途":"tdtype", "出让面积":"crmj", "容积率":"rjl", "出让状态":"blockstate", "竞得价":"jdj", "竞得日期":"jdrq", "竞得人":"jdr"}
url = 'http://www.shtdsc.com/2016/tdjy/dkxx/crdk/?id=' + num
browser = webdriver.Firefox()
browser.get(url)
time.sleep(2)
for key in lablename.keys():
landdata[key] = browser.find_element(by='id', value=lablename[key]).text
运行结果及报错内容
浏览器页面显示额范围是这些:
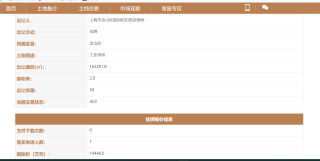
然后函数执行的打印结果只如下这几个值:
{'地块名称': '', '四至范围': '', '出让人': '上海市金山区规划和自然资源局', '出让方式': '挂牌', '所属区县': '金山区', '土地用途': '工业用地', '出让面积': '162201.8', '容积率': '2.0', '出让状态': '成交', '竞得价': '', '竞得日期': '', '竞得人': ''}
浏览器页面不显示的地方,数据的值就爬取不到
这是为什么呀?








