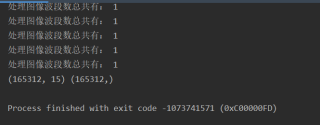
问题遇到的现象和发生背景
运行时出现栈溢出的现象,试过网上大家说的修改栈大小、深度等,但都没有解决问题。我的数据有16万多条,不知道是不是数据太大的问题,还是其他问题。
问题相关代码,请勿粘贴截图
import numpy as np
import sys
import os
from osgeo import gdal
from sklearn import ensemble
from sklearn.model_selection import train_test_split
import joblib
from tqdm import tqdm
import time
# 显示进度条
text = ""
for char in tqdm(["a", "b"]):
text = text + char
time.sleep(0.5)
# 读取tif数据
def Read_img2array(img_file_path):
"""
读取栅格数据,将其转换成对应数组
img_file_path: 栅格数据路径
:return: 返回投影,几何信息,和转换后的数组
"""
dataset = gdal.Open(img_file_path) # 读取栅格数据
print('处理图像波段数总共有:', dataset.RasterCount)
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
# 直接读取dataset
img_array = dataset.ReadAsArray()
return img_array
# tif -> array
def read_tif_array(path, filetype):
pathDir = os.listdir(path) # 文件放置在当前文件夹中,用来获取当前文件夹内所有文件目录
i = 0
array = [[0] * 1] * 165312
array = np.array(array)
array = array.reshape(-2, 1)
for x in pathDir:
index = x.rfind('.')
if x[index:] == filetype:
img_array = Read_img2array(path + "/" + x)
mul = np.array(img_array).reshape(-2, 1)
array = np.column_stack((array, mul))
i = i + 1
else:
i = i
array = array[:, 1:]
return array
# 读取特征值
feature = read_tif_array("D:/Personality/paper/GBDT/train", '.tif')
# print(feature.shape) # 一共有15个特征值
# 读取地质类为标签
label = read_tif_array("D:/Personality/paper/GBDT/label", '.tif')
label = label.ravel()
print(feature.shape, label.shape)
X, y = feature, label
labels, y = np.unique(y, return_inverse=True) # 标签
X_train, X_test, y_train, y_test = train_test_split(X, y) # 创建数据集
original_params = {
"n_estimators": 400,
"max_leaf_nodes": 4,
"max_depth": 6,
"random_state": 2,
"min_samples_split": 5,
} # 设置树的基本参数,用于后面计算
setting = {"learning_rate": 0.2, "subsample": 1.0}
params = dict(original_params) # 转化为字典
params.update(setting) # 更新字典键值对
clf = ensemble.GradientBoostingClassifier(**params) # 梯度
clf.fit(X_train, y_train) # 训练数据集
joblib.dump(clf, 'train_model_result.m') # 保存模型
y_gbr = clf.predict(X_train)
y_gbr1 = clf.predict(X_test)
acc_train = clf.score(X_train, y_train)
acc_test = clf.score(X_test, y_test)
print(acc_train)
print(acc_test)
运行结果及报错内容