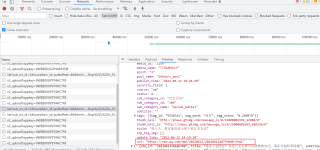
刚刚学习python,代码不报错,但是没有输出结果,不知道为什么,求大家喵一眼!就二十多行代码!
代码如下
import requests
from bs4 import BeautifulSoup
url="http://news.qq.com/"
请求腾讯新闻的URL,获取其text文本
wbdata=requests.get(url).text
对获取到的文本进行解析
soup=BeautifulSoup(wbdata,'lxml')
从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles=soup.select("div.text > em.f14 > a.linkto")
对返回的列表进行遍历
for n in news_titles:
title=n.get_text()
link=n.get("href")
data={ '标题':title, '链接':link}
print(data)