# coding:utf-8
# __auth__ = "maiz"
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
import math
import requests
import lxml
import re
import time
# 构造url字典
area_dic = {#'罗湖区':'luohuqu',
#'福田区':'futianqu',
'南山区':'nanshanqu',
#'盐田区':'yantianqu',
#'宝安区':'baoanqu',
#'龙岗区':'longgangqu',
#'龙华区':'longhuaqu',
#'坪山区':'pingshanqu'
}
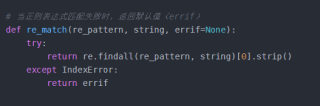
# 当正则表达式匹配失败时,返回默认值(errif)
def re_match(re_pattern, string, errif=None):
try:
return re.findall(re_pattern, string)[0].strip()
except IndexError:
return errif
# 主函数部分,
# 通过request获取源码,
# 通过正则表达式提取相应的字段,
# 通过BeautifulSoup包获取房子的信息,
# DataFrame存储信息
data = pd.DataFrame()
for key_, value_ in area_dic.items():
# 加个header进行伪装
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Referer': 'https://sz.lianjia.com/ershoufang/'}
# 新建一个会话
sess = requests.session()
sess.get('https://sz.lianjia.com/ershoufang/', headers=headers)
# url示例:https://sz.lianjia.com/ershoufang/luohuqu/pg2/
url = 'https://sz.lianjia.com/ershoufang/{}/pg{}/'
# 获取该行政区下房源记录数
start_url = 'https://sz.lianjia.com/ershoufang/{}/'.format(value_)
html = sess.get(start_url).text
# print(html[:100])
print(re.findall('共找到<span> (.*?) </span>套.*二手房', html))
house_num = re.findall('共找到<span> (.*?) </span>套.*二手房', html)[0].strip()
print('{}: 二手房源共计{}套'.format(key_, house_num))
time.sleep(1)
# 页面限制 每个行政区只能获取最多100页共计3000条房源信息
total_page = int(math.ceil(min(3000, int(house_num)) / 30.0))
for i in tqdm(range(total_page), desc=key_):
html = sess.get(url.format(value_, i+1)).text
soup = BeautifulSoup(html, 'lxml')
info_collect = soup.find_all(class_="info clear")
for info in info_collect:
info_dic = {}
# 行政区
info_dic['area'] = key_
# 房源的标题
info_dic['title'] = re_match('target="_blank">(.*?)</a><!--', str(info))
# 小区名
info_dic['community'] = re_match('xiaoqu.*?target="_blank">(.*?)</a>', str(info))
# 位置
info_dic['position'] = re_match('<a href.*?target="_blank">(.*?)</a>.*?class="address">', str(info))
# 税相关,如房本满5年
info_dic['tax'] = re_match('class="taxfree">(.*?)</span>', str(info))
# 总价
info_dic['total_price'] = float(re_match('class="totalPrice totalPrice2"><span>(.*?)</span>万', str(info)))
# 单价
info_dic['unit_price'] = float(re_match('data-price="(.*?)"', str(info)))
# 匹配房源标签信息,通过|切割
# 包括面积,朝向,装修等信息
icons = re.findall('class="houseIcon"></span>(.*?)</div>', str(info))[0].strip().split('|')
info_dic['hourseType'] = icons[0].strip()
info_dic['hourseSize'] = float(icons[1].replace('平米', ''))
info_dic['direction'] = icons[2].strip()
info_dic['fitment'] = icons[3].strip()
# 存入DataFrame
if data.empty:
data = pd.DataFrame(info_dic, index=[0])
else:
data = data.append(info_dic, ignore_index=True)
# 去掉面积10000+平米的房源记录(离群值),查看我们爬取到的信息
data = data[data['hourseSize'] < 10000]
data.head()
print(data)
...