问题遇到的现象和发生背景
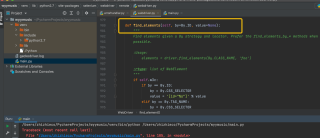
问题相关代码,请勿粘贴截图
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
import time, random
import threading
# 用户id
userId = '120091509'
userName = '宇航员柯智泷'
songsAll = []
songs10 = []
songs = []
# 获取播放排行前100
def getSongs100ByUserId():
options = webdriver.ChromeOptions()
# selenium反爬
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
# 无头模式
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
url = 'https://music.163.com/#/user/home?id={userId}'
browser.get(url)
browser.refresh()
browser.switch_to.frame('g_iframe')
time.sleep(2)
browser.find_element(by=By.ID, value='songsall').click()
time.sleep(2)
browser.find_element(by=By.XPATH, value='*//div[@class="more"]/a[1]').click()
time.sleep(2)
browser.find_element(by=By.ID, value='songsall').click()
time.sleep(2)
# 获取歌id
idList = browser.find_elements(by=By.XPATH, value='*//span[@class="txt"]/a')
# 获取歌名
nameList = browser.find_elements(by=By.XPATH, value='*//span[@class="txt"]/a/b')
for id, name in zip(idList, nameList):
realId = (int)(id.get_attribute('href').split('=')[1])
realName = name.text
song = {"name": realName, "id": realId}
songsAll.append(song)
browser.close()
# 获取某个歌单的所有歌
js = "var q=document.documentElement.scrollTop=1000000"
# 打开浏览器获取评论
def getComents(song):
options = webdriver.ChromeOptions()
# selenium反爬
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
# 无头模式
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
url = 'https://music.163.com/#/song?id=32957955'
browser.get(url)
time.sleep(3)
browser.switch_to.frame('g_iframe')
# 评论总页数
total = int(browser.find_element(by=By.XPATH, value='*//div[@class="m-cmmt"]/div[3]/div/a[10]').text)
if total > 4000:
total = int(total / 4 * 3)
if total > 1:
for i in range(1, total):
# 所有评论
texts = browser.find_elements(by=By.XPATH, value='//div[@class="cnt f-brk"]')
# 评论时间
times = browser.find_elements(by=By.XPATH, value='//div[@class="rp"]')
# 评论人a标签,从中获取userid
aList = browser.find_elements(by=By.XPATH, value='//div[@class="cnt f-brk"]/a')
for text, timeC, a in zip(texts, times, aList):
artice = text.text.split(':')
sp = '\n'
uid = a.get_attribute("href").split('=')[1]
if artice[0] == userName:
if uid == userId:
# 展示xx用户的评论(具体评论+时间时间)
comment = """{artice[1]} 时间:{timeC.text.split(sp)[0]}"""
f = open("comments.txt", "a+", encoding='utf-8')
f.seek(0)
strAll = f.read()
if strAll.__contains__(comment) is False:
commentAndSongName = """\n歌曲:{song["name"]}\n第{str(i)}页:{artice[1]} 时间:{timeC.text.split(sp)[0]}"""
f.write(commentAndSongName)
# 关闭打开的文件
f.close()
print("歌曲:" + song["name"])
print('第' + str(i) + '页:' + artice[1] + ' 时间:' + timeC.text.split('\n')[0])
browser.execute_script(js)
browser.find_element(by=By.XPATH, value='*//div[@class="m-cmmt"]/div[3]/div/a[11]').click()
time.sleep(random.randint(1, 3))
browser.close()
if __name__ == '__main__':
getSongs100ByUserId()
if songsAll.__len__() > 10:
songs10 = songsAll[0:10]
songs = songsAll[10:]
threads = []
for song in songs10:
tk = threading.Thread(target=getComents, args=(song,))
threads.append(tk)
for ts in threads:
ts.start()
time.sleep(2)
while songs.__len__() > 0:
for song in songs:
finish = False
for t in threads:
if t.is_alive() is False:
threads.remove(t)
finish = True
if finish is True:
tt = threading.Thread(target=getComents, args=(song,))
threads.append(tt)
tt.start()
songs.remove(song)
我的解答思路和尝试过的方法
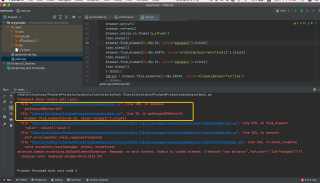
方法我点进去看过了,没问题啊?
报错信息:
<iframe name="contentFrame" id="g_iframe" class="g-iframe" scrolling="auto" frameborder="0" src="about:blank" allowfullscreen="true" cd_frame_id_="f658a861dec41632d9c392afd1fc2f32"></iframe> is not clickable at point (771, 593). Other element would receive the click: <div class="left f-fl">...</div>
(Session info: headless chrome=104.0.5112.79)
iframe我又没用click()方法,为什么他会跟我说这个元素不可点击呢?我想点击这个iframe里的按钮