import pandas as pd
df = pd.DataFrame()
for i in range(1, 5):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}%27'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]])
# df['代码'].apply(str)
# df['代码'] = df['代码'].astype(str)
# df['代码'] = df['代码'].apply(lambda _: str(_))
df['代码'] = df['代码'].map(lambda x:('%06d')%x).apply(str)
df.to_csv('新浪财经基金重仓股数据4.csv', encoding='utf_8_sig', index=False)
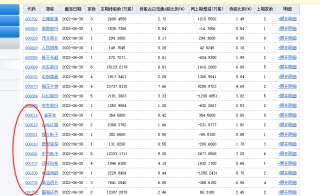
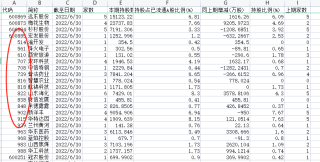
执行代码后,如下图所示,csv文件中的第一列的开头的已经保存了下来。
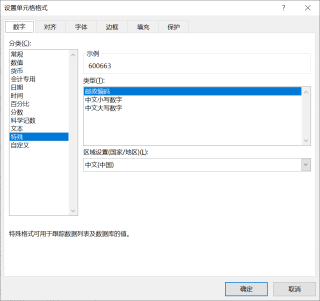
使用excel打开生成的csv文件后,第一列仍然不显示前面的0,可以选中第一列之后,鼠标右键“设置单元格格式”,再点击确定即可,如下:
当然还可以在第一列的文本前增加一个前缀,比如一个字母A,或一个单引号,python导出csv文件之后,直接用ecxel打开,无需其他设置。
import pandas as pd
df = pd.DataFrame()
for i in range(1, 5):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}%27'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]])
df['代码'] = df['代码'].map(lambda x:('%06d') % x).apply(str)
# df['代码'] = "'" + df['代码']
# 或
df['代码'] = "A" + df['代码']
df.to_csv(r'd:\新浪财经基金重仓股数据4.csv', encoding='utf_8_sig', index=False)