
· 问题遇到的现象和发生背景
在进行data merge的时候,输出的结果将同一数据重复了两次,并且重复的数据列的尾标多了_x或_y,请问要怎么解决或者删除重复的列呢?
· 用代码块功能插入代码,请勿粘贴截图
wr = data_wr.rename(columns = {'name':'country'})
int_of_form = gdp.merge(ley,on=['country','year'])
int_of_form = int_of_form.merge(hdi,on=['country','year'])
int_of_form = int_of_form.merge(ipp,on=['country','year'])
int_of_form = int_of_form.merge(ths,on=['country','year'])
int_of_form = int_of_form.merge(hs,on=['country','year'])
int_of_form = int_of_form.merge(wr[['country','region','sub-region']],on=['country'])
int_of_form
· 运行结果及报错内容
C:\Users\jinge\AppData\Local\Temp\ipykernel_27048\1158664028.py:1: FutureWarning: Passing 'suffixes' which cause duplicate columns {'sub-region_x', 'region_x'} in the result is deprecated and will raise a MergeError in a future version.
int_of_form = int_of_form.merge(wr[['country','region','sub-region']],on=['country'])
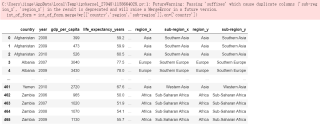
· 我想要达到的结果
将region_x、region_y、sub-region_x、sub-region_y这四列处理成region和sub-region两列









