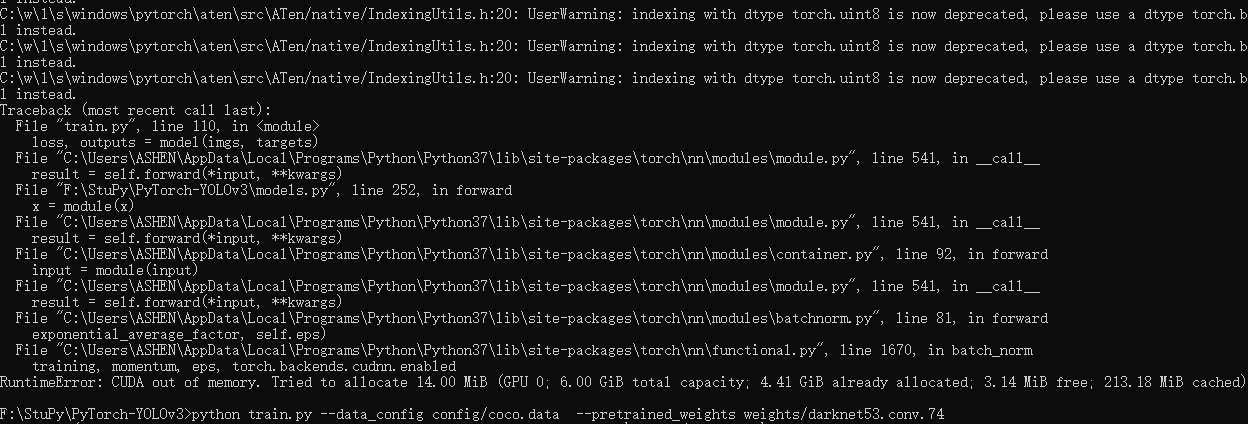
报错信息 RuntimeError: CUDA out of memory. Tried to allocate 14.00 MiB (GPU 0; 6.00 GiB total capacity; 4.41 GiB already allocated; 3.14 MiB free; 213.18 MiB cached)
GPU 0是核显
GPU 1是独显

报错信息 RuntimeError: CUDA out of memory. Tried to allocate 14.00 MiB (GPU 0; 6.00 GiB total capacity; 4.41 GiB already allocated; 3.14 MiB free; 213.18 MiB cached)
GPU 0是核显
GPU 1是独显
 分享
分享
以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
要解决这个问题,您需要确保您的计算机有足够的内存来运行模型。此外,您可能需要调整网络的配置,例如将数据集大小减小或使用更高效的优化器。
以下是一个简单的例子,展示了如何在Windows上安装CUDA和PyTorch,并进行独显训练:
# 安装CUDA
pip install pytorch-cuda
然后,在命令行中,您可以尝试运行以下代码:
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch import nn, optim
import torch.nn.functional as F
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 加载数据集
dataset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=100, shuffle=True)
# 定义模型
model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(7*7*64, 512),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(512, 10),
nn.LogSoftmax(dim=1)
)
# 定义损失函数和优化器
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练模型
for epoch in range(10):
for i, (images, labels) in enumerate(dataloader):
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
# 反向传播和优化
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{10}], Step [{i+1}/{len(dataloader)}], Loss: {loss.item():.4f}')
这段代码首先加载了CIFAR-10数据集并将其转换为Tensor张量。然后,它定义了一个简单的卷积神经网络(CNN),其中包含两个卷积层、一个池化层以及全连接层。最后,它使用SGD作为优化器,并对每个epoch中的所有批次进行训练。
请注意,这只是一个基本示例,实际应用中可能会涉及更多的参数调整和实验。
分享

