
1、
环境:pycharm
浏览器:chrome
描述:使用selenium爬取某宝数据,爬虫代码能正常运行(可以对元素进行定位,可以下拉滑动条、可以通过修改url去到下一页),但是控制台只打印了一个商品的信息,其余爬取的信息没有被打印出来
2、代码如下:
"""
爬取淘宝商品步骤:
1、打开谷歌浏览器,访问淘宝网站:找到淘宝的 url
2、定位搜索框和搜索按钮(F12,使用元素选择器进行定位,复制 XPath),要完成的动作→输入要搜索的商品,然后点击搜索按钮
3、在登陆界面停留 10 秒,手机扫码登陆(需手动),高级一点的方法可以自送输入账号密码登陆
4、进入搜索结果页面,模仿人浏览商品时的动作→下拉滑动条到页面的最后,拉5次,拉的过程有暂停
"""
from selenium import webdriver
# 需要一款浏览器,访问淘宝网址
import time
import re
# 找到 输入框 找到 按钮
# 元素(输入框、按钮等) 定位
def search_product():
driver.find_element_by_xpath('//*[@id="q"]').send_keys(kw)
driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
# # 强行阻止程序运行 10s的时间
time.sleep(5)
# 获取搜索结果页面的总页码
token = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text
token = int(re.compile('(\d+)').search(token).group(1))
return token
# 元素定位 他没有前提吗?你的网速比较慢,如果元素没有加载完毕,那么你能够去定位没有加载的数据吗?没有加载出来
# 也就是说,这个加载的过程 是因为我拉动了下滑条!
# 步骤:登录 拉动下滑条 采集数据 下一页 拉动下滑条 再采集数据,按这个循环!
def drop_down():
# 一次拉一部分,拉的时候有暂停 range 得出 1 3 5 7 9 五个数
for x in range(1, 11, 2):
time.sleep(0.5)
# j 代表滑动条的五个位置:1/10、3/10、5/10、7/10、9/10
j = x/10
# 下面的 js 是 JavaScript 的语法,可以当作万能公式解决大部分网站问题
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)
def get_product():
# 首先获取所有的 div ,然后遍历所有的 div ,得到一个div 再去一个 div 里面寻找需要的数据
# // 代表任意位置(任意一个位置的属性属于 class="items" 的 div)
# //div[@]/div[@] 代表要获取的 div 的路径
divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq item-ad "]')
for div in divs:
# . 代表当前目录, .// 当前目录下的任意 div标签 下的 a标签 下的 img标签 下的 src
info = div.find_element_by_xpath('.//div[@class="row row-2 title"]').text
price = div.find_element_by_xpath('.//div[@class="price g_price '
'g_price-highlight"]/strong').text + '元'
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text
image = div.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src')
# name = div.find_element_by_xpath('.//div[@class="shop"/a/span[1]').text
address = div.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="location"]').text
# 定义一个字典
product = {'标题': info, '价格': price, '订单量': deal, '图片': image, '地址': address}
print(product)
# 淘宝的反爬很严重,所以尽量不要模拟多次点击下一页
# 采用改 url 的方法可以避免反爬:通过分析淘宝页面的 url→https://s.taobao.com/search?q=Python&s=88
# 可以得知下一页就是在 url 后面的值 +44。即第4页的 url 为 https://s.taobao.com/search?q=Python&s=132
def next_page():
token = search_product()
drop_down()
get_product()
num = 1
while num != token:
driver.get('https://s.taobao.com/search?q={}&s={}'.format(kw, 44*num))
num += 1
# time.sleep(4) 。这个方法延迟太慢了,改用下面的只能等待方法
# 隐视等待,智能等待,最高等待时间为10s,如果超过10s,抛出异常
driver.implicitly_wait(10)
# 无限循环进入网页,可能造成网页卡顿!导致数据加载不出来,解决方法是加一个延迟,等数据先加载出来再操作
drop_down()
get_product()
if __name__ == '__main__':
kw = input('请输入你想查询的商品:')
driver = webdriver.Chrome()
driver.get('https://www.taobao.com/')
next_page()
# 这个程序可以无限制地爬取内容,淘宝无法检测出来而反爬
3、代码能正常运行,打印信息如下: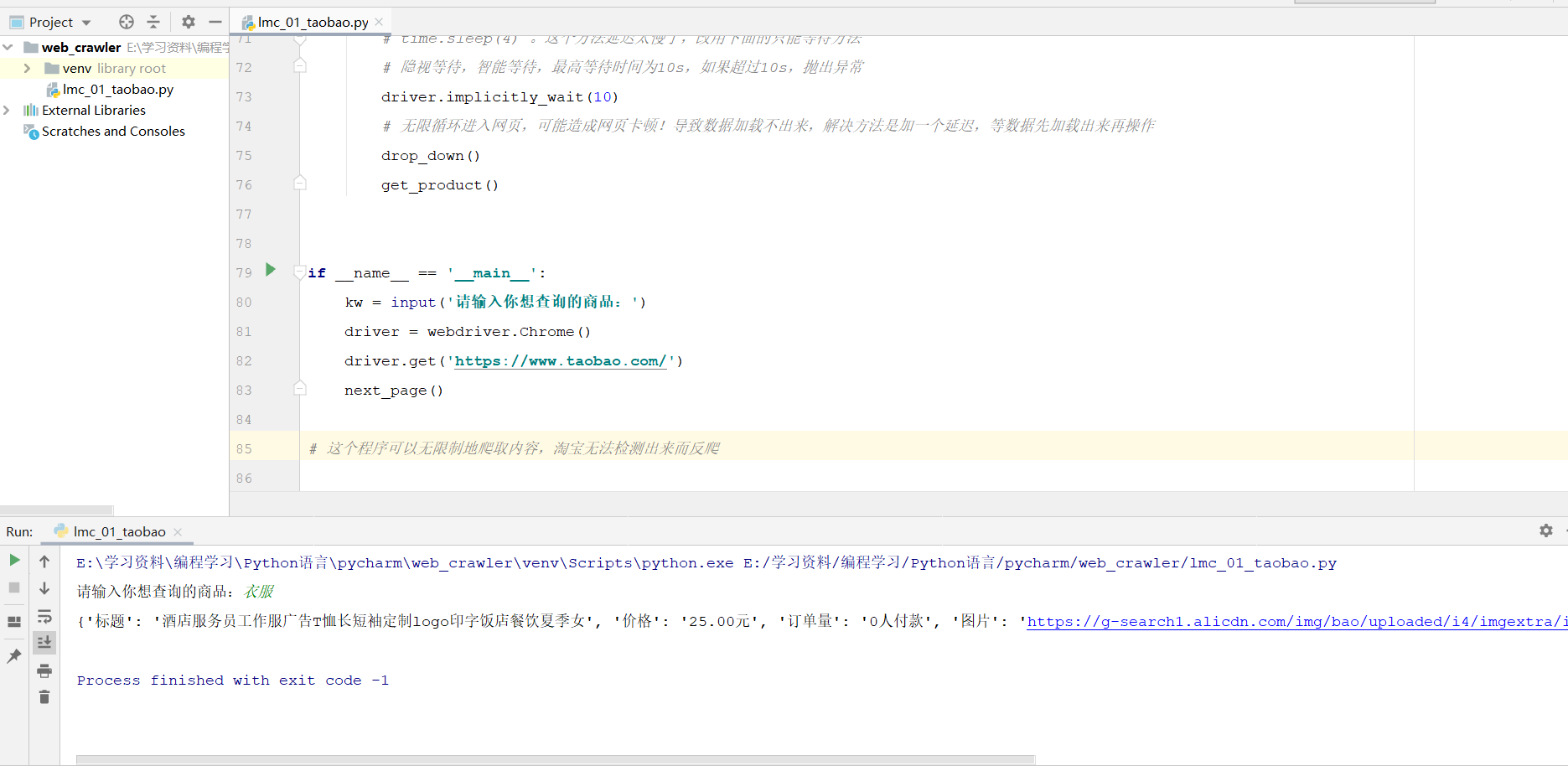
4、求各位大神帮忙解决一下T-T






