
起初是用xpath进行数据爬虫
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36"}
response = requests.get('https://www.gia.edu/CN/report-check?_=2&reportno=7348210118',headers=headers)
contents = etree.HTML(response.text)
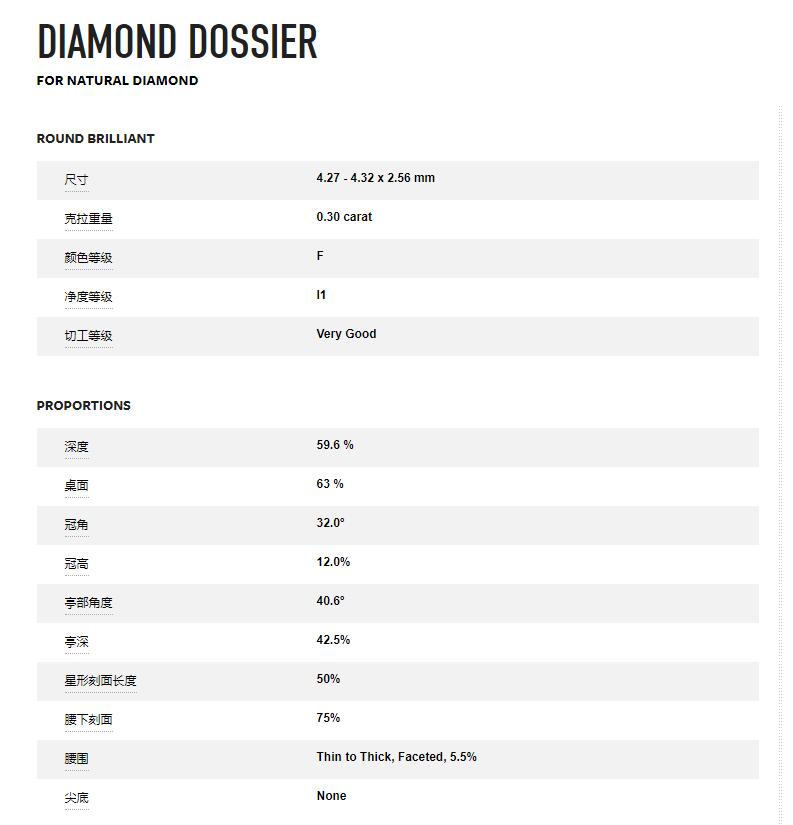
发现数据不对,页面上的数据是通过JS加载出来的。
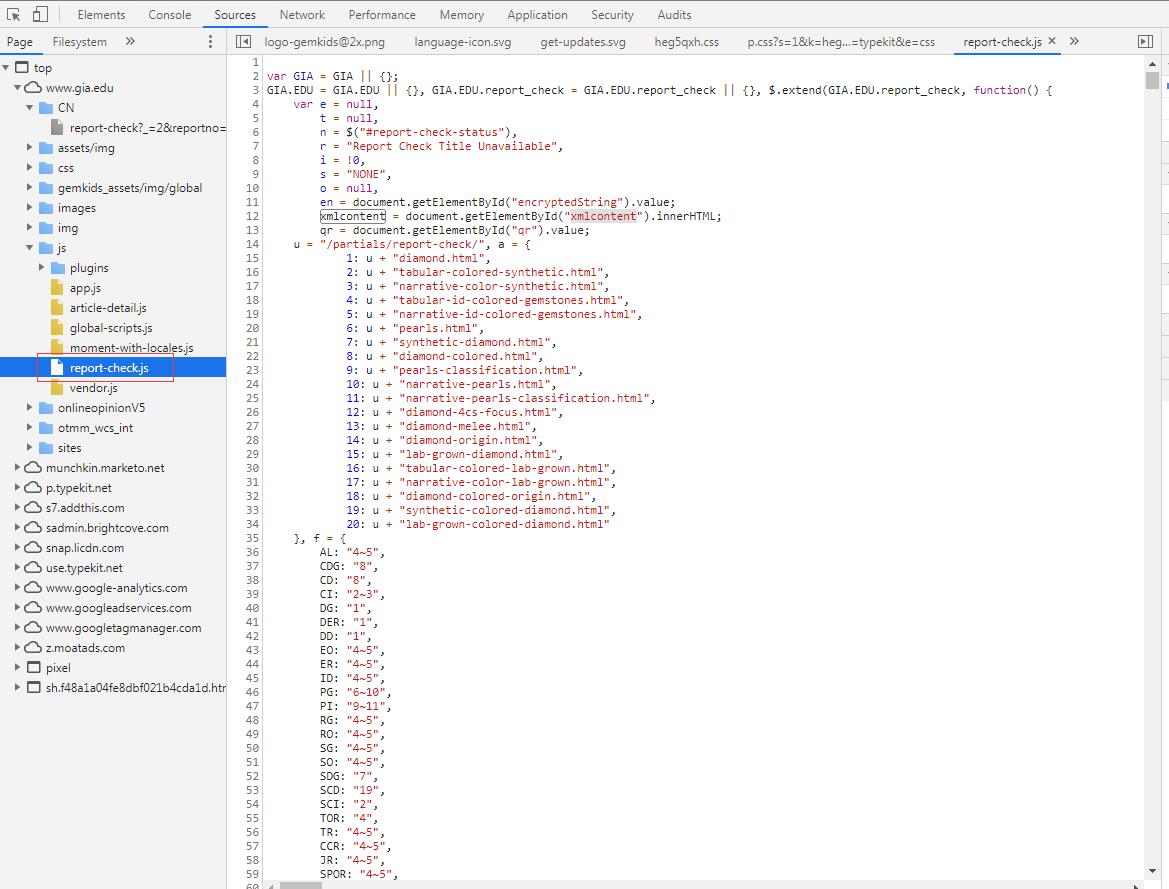
后来通过分析数据来源,找到了数据加载是在这个JS文件中完成,并且数据是在页面中ID为xmlcontent的标签内容中,但是xmlcontent标签是设置的隐藏。
网上查阅资料说是用selenium可以获取隐藏标签
driver = webdriver.PhantomJS(executable_path=r'D:\python_tools\phantomjs-2.1.1-windows\bin\phantomjs.exe')
driver.get('https://www.gia.edu/CN/report-check?reportno=6335838911')
xmlcontent = driver.find_element_by_id('xmlcontent')
print(xmlcontent.get_attribute('innerHTML'))
但是貌似效果不理想,初学者往各位大佬指点~~~




