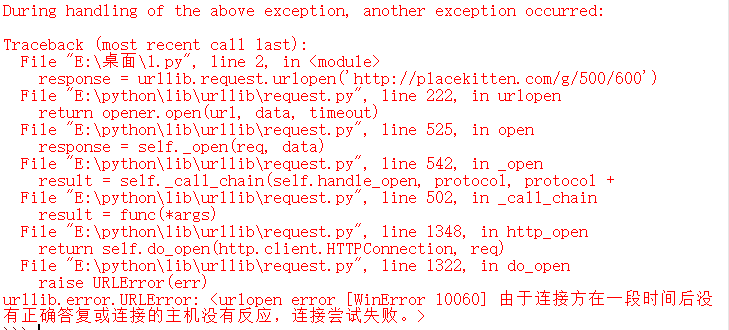
import urllib.request
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
cat_img = response.read()
with open('cat_500_600.jpg','wb') as f:
f.write(cat_img)

import urllib.request
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
cat_img = response.read()
with open('cat_500_600.jpg','wb') as f:
f.write(cat_img)
 分享
分享



