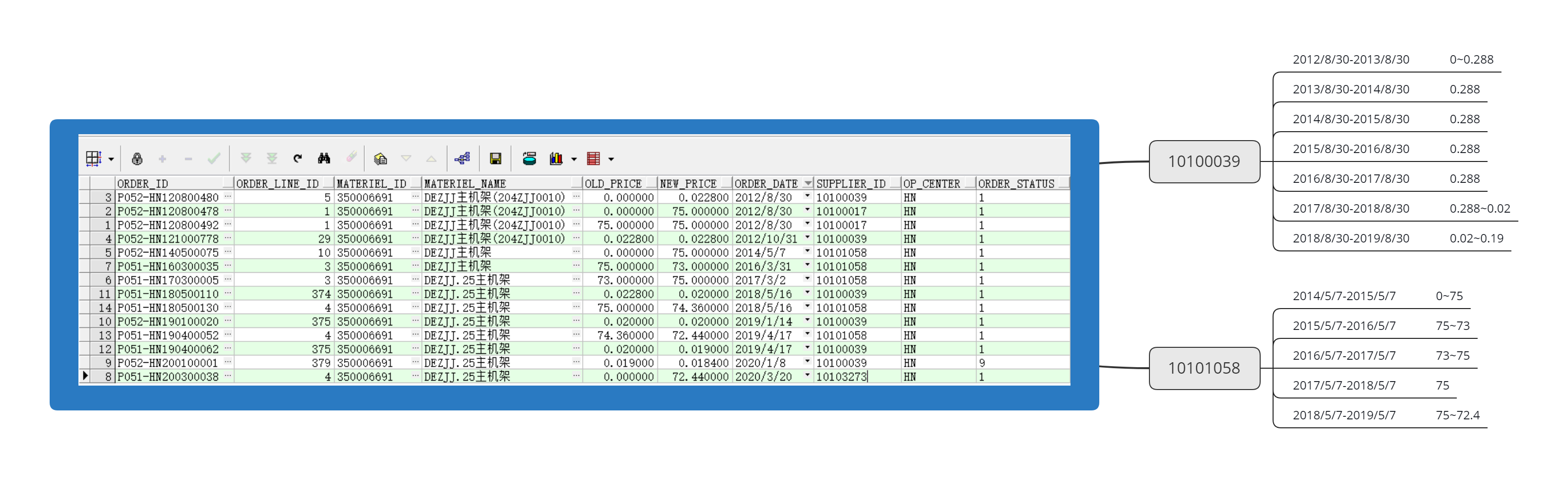
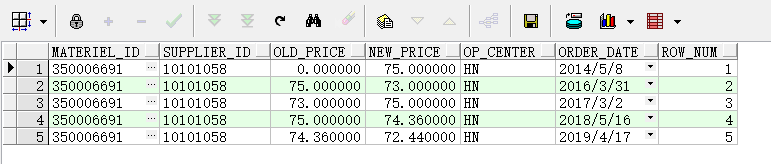
如图1所示,同一个MATERIEL_ID有多个SUPPLIER_ID的多个价格变动记录(OLD_PRICE/NEW_PRICE)(根据日期ORDER_DATE)。为了举例,挑选了SUPPLIER_ID=10101058的价格记录,需要根据最早的价格生成时间2014/5/7,每12个月为一个周期,将价格变动情况匹配到相应周期中去。上一个周期的NEW_PRICE,默认为下个周期开始的OLD_PRICE。若某个周期无对应价格变动记录,默认取上个周期的NEW_PRICE为该周期的价格(如2017/5/7~2018/5/7这个周期)。
目前我已经将需要的数据做成了两个视图,图二为实际的价格变动记录。图三为最终需要的结构,需要填充价格区间。考虑了下需要用存储过程做双循环来实现,该怎么做?