
在运行.sh文件时报以下错误(cuda10.0、cudnn7.3以及tensorflow1.14)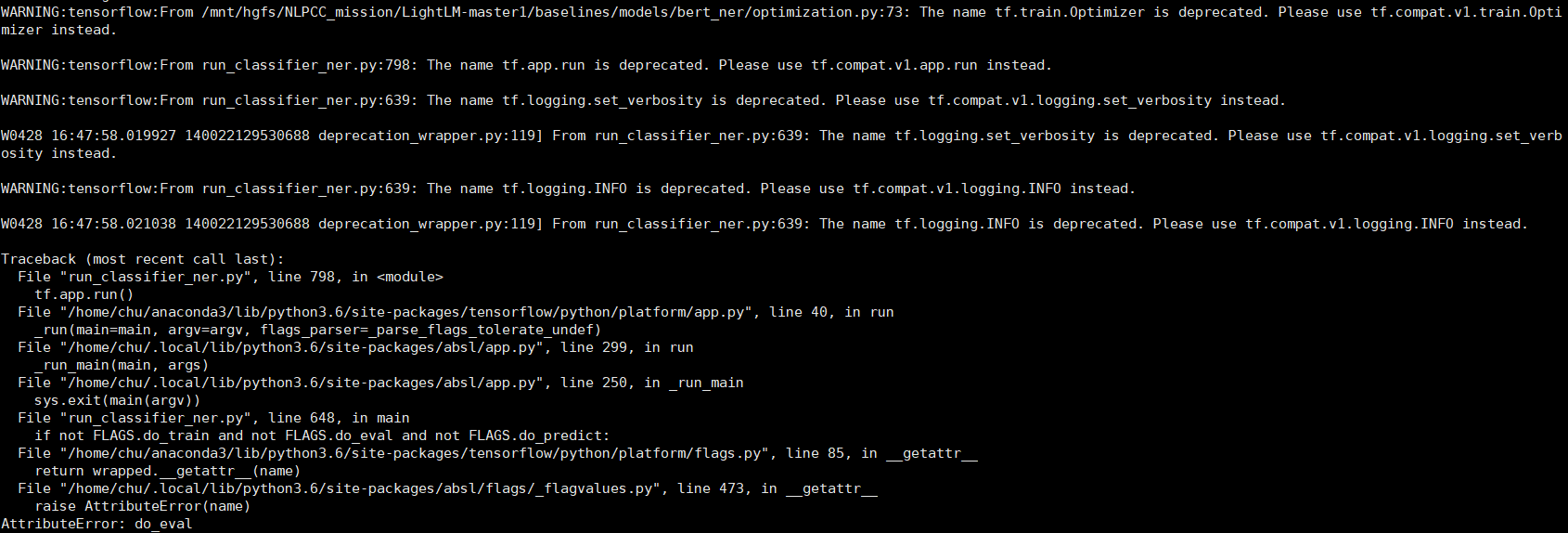
ps:运行的文件代码
#!/usr/bin/env bash
@Author: bo.shi
@Date: 2019-11-04 09:56:36
@Last Modified by: bo.shi
@Last Modified time: 2019-12-05 11:23:30
TASK_NAME="ner"
MODEL_NAME="chinese_roberta_wwm_large_ext_L-24_H-1024_A-16"
CURRENT_DIR=$(cd -P -- "$(dirname -- "$0")" && pwd -P)
export CUDA_VISIBLE_DEVICES="0"
export PRETRAINED_MODELS_DIR=$CURRENT_DIR/prev_trained_model
export ROBERTA_WWM_LARGE_DIR=$PRETRAINED_MODELS_DIR/$MODEL_NAME
export GLUE_DATA_DIR=$CURRENT_DIR/CLUEdataset
download and unzip dataset
if [ ! -d $GLUE_DATA_DIR ]; then
mkdir -p $GLUE_DATA_DIR
echo "makedir $GLUE_DATA_DIR"
fi
cd $GLUE_DATA_DIR
if [ ! -d $TASK_NAME ]; then
mkdir $TASK_NAME
echo "makedir $GLUE_DATA_DIR/$TASK_NAME"
fi
cd $TASK_NAME
if [ ! -f "train.json" ] || [ ! -f "dev.json" ] || [ ! -f "test.json" ]; then
rm *
wget https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip
unzip cluener_public.zip
rm cluener_public.zip
else
echo "data exists"
fi
echo "Finish download dataset."
download model
if [ ! -d $ROBERTA_WWM_LARGE_DIR ]; then
mkdir -p $ROBERTA_WWM_LARGE_DIR
echo "makedir $ROBERTA_WWM_LARGE_DIR"
fi
cd $ROBERTA_WWM_LARGE_DIR
if [ ! -f "bert_config.json" ] || [ ! -f "vocab.txt" ] || [ ! -f "bert_model.ckpt.index" ] || [ ! -f "bert_model.ckpt.meta" ] || [ ! -f "bert_model.ckpt.data-00000-of-00001" ]; then
rm *
wget -c https://storage.googleapis.com/chineseglue/pretrain_models/chinese_roberta_wwm_large_ext_L-24_H-1024_A-16.zip
unzip chinese_roberta_wwm_large_ext_L-24_H-1024_A-16.zip
rm chinese_roberta_wwm_large_ext_L-24_H-1024_A-16.zip
else
echo "model exists"
fi
echo "Finish download model."
run task
cd $CURRENT_DIR
echo "Start running..."
python run_classifier_roberta_wwm_large.py \
--task_name=$TASK_NAME \
--do_train=true \
--do_predict=true \
--data_dir=$GLUE_DATA_DIR/$TASK_NAME \
--vocab_file=$ROBERTA_WWM_LARGE_DIR/vocab.txt \
--bert_config_file=$ROBERTA_WWM_LARGE_DIR/bert_config.json \
--init_checkpoint=$ROBERTA_WWM_LARGE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=4.0 \
--output_dir=$CURRENT_DIR/${TASK_NAME}_output






