
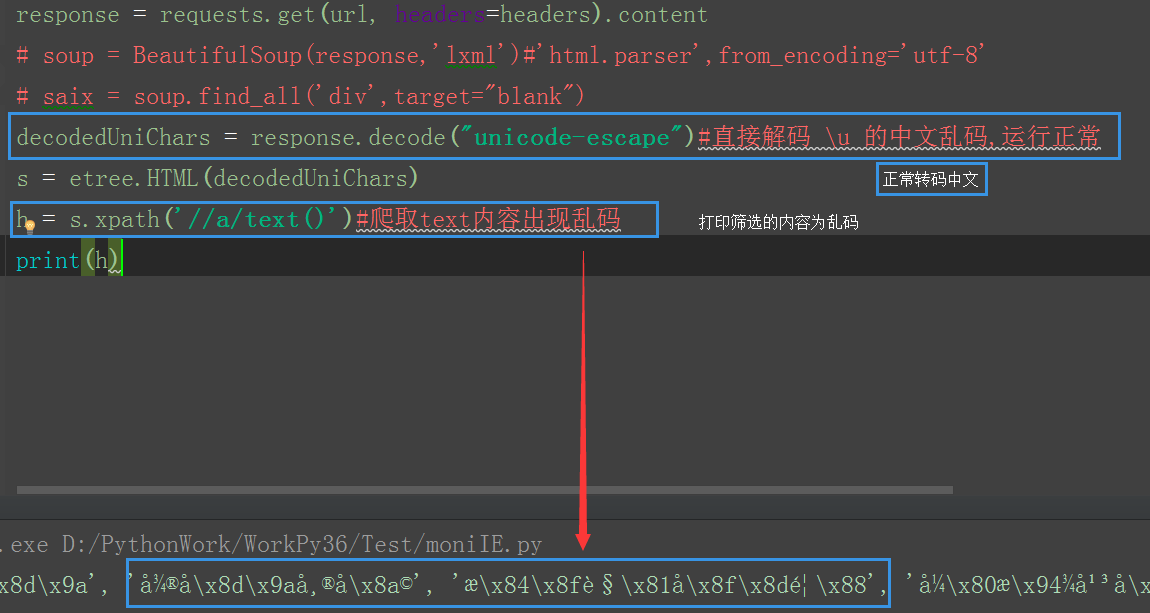
response = requests.get(url, headers=headers).content
# soup = BeautifulSoup(response,'lxml')#'html.parser',from_encoding='utf-8'
# saix = soup.find_all('div',target="blank")
decodedUniChars = response.decode("unicode-escape")#直接解码 \u 的中文乱码,运行正常
s = etree.HTML(decodedUniChars)
h = s.xpath('//a/text()')#爬取text内容出现乱码
print(h) 打印text内容出现乱码
没什么C币 抱歉了







