使用的是python3
我觉得应该是这个
imglist = re.findall(imgre,html)
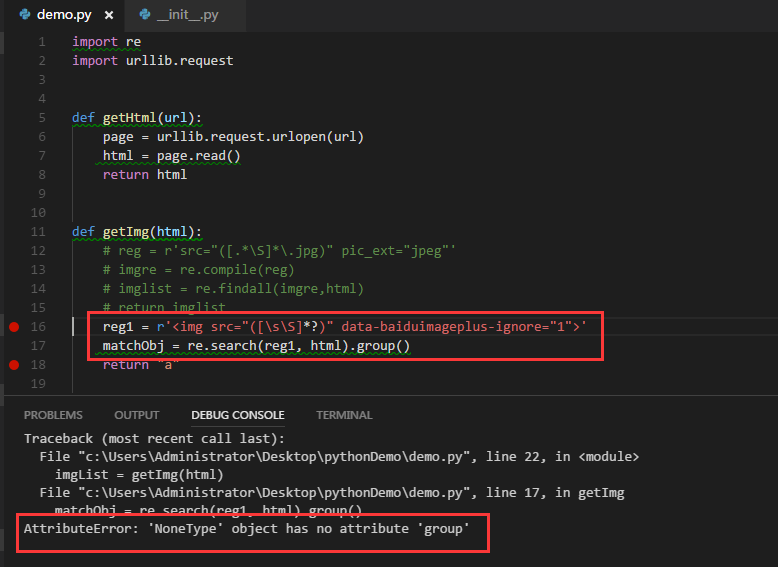
语法不对
谁知道正确的语法是什么
哪位大神能帮改下
import re
import urllib.request
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
def getImg(html):
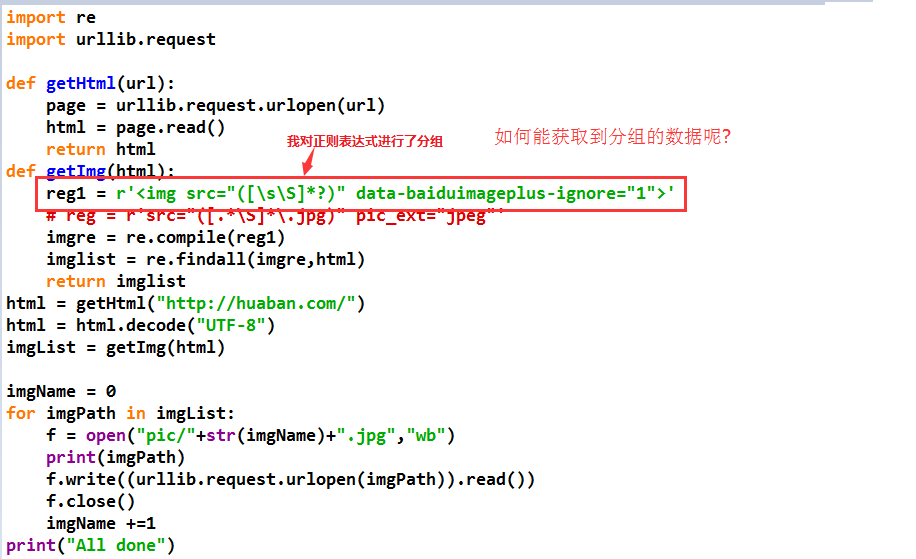
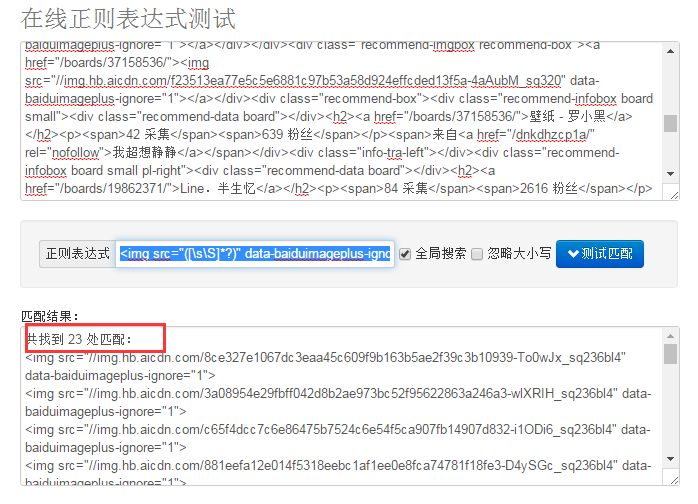
reg1 = r'<img src="([\s\S]*?)" data-baiduimageplus-ignore="1">'
g0 = re.search(reg1,html).group(0)
print(g0)
# reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
# imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
html = getHtml("http://huaban.com/")
html = html.decode("UTF-8")
imgList = getImg(html)
imgName = 0
for imgPath in imgList:
f = open("pic/"+str(imgName)+".jpg","wb")
print(imgPath)
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName +=1
print("All done")
有了一点进展
网上有人说用search
我找了一个demo,并修改了我的代码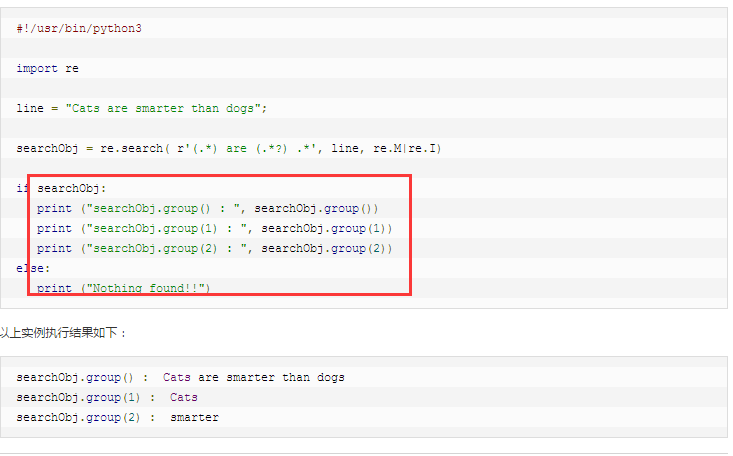
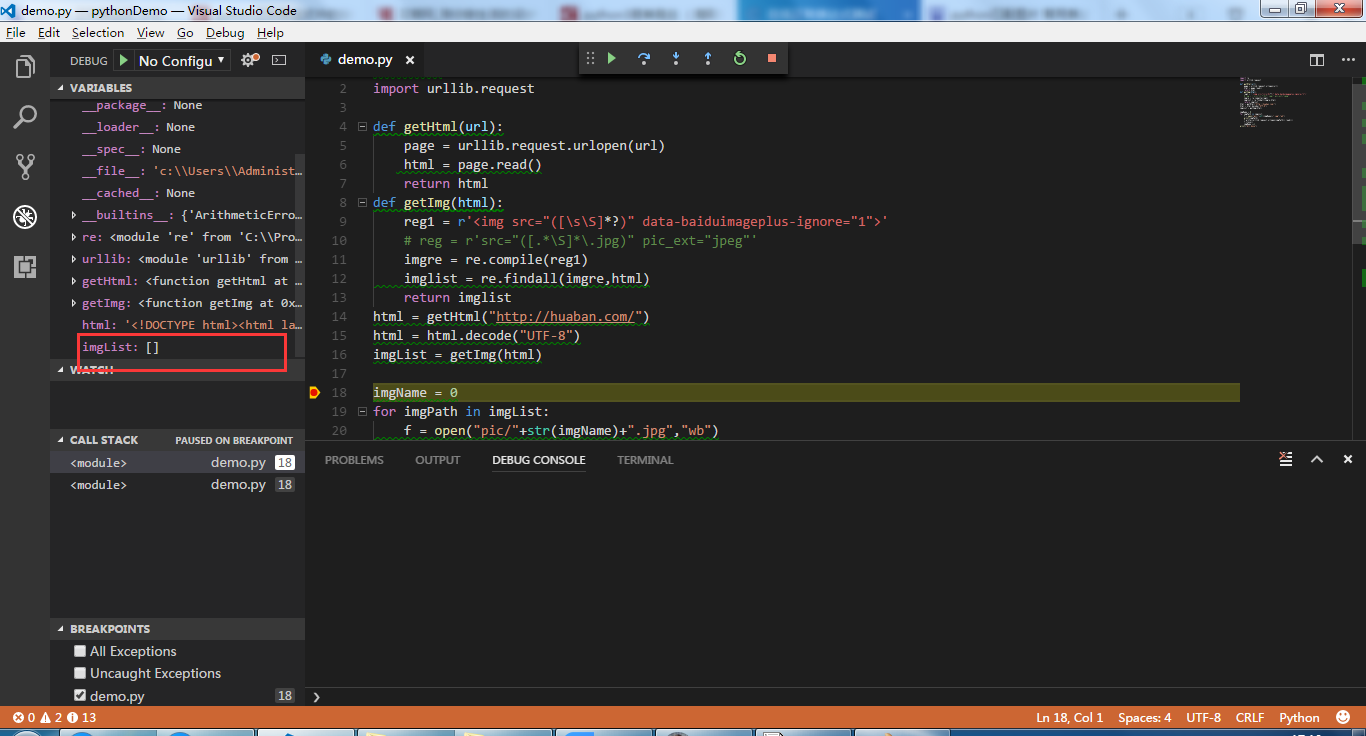
但是还是报错