
#**_ scrapy代码运行成功却没有保存到文件中_**
代码: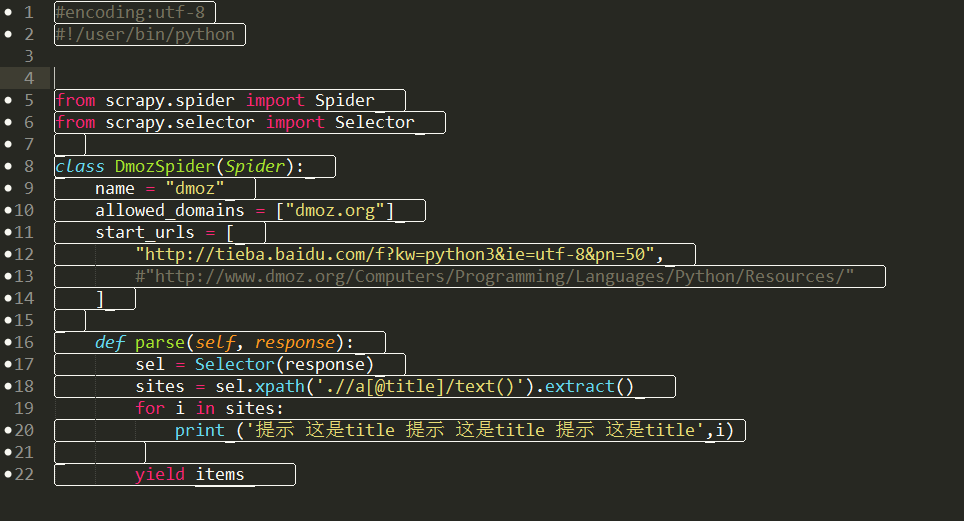
#encoding:utf-8
#!/user/bin/python
from scrapy.spider import Spider
from scrapy.selector import Selector
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://tieba.baidu.com/f?kw=python3&ie=utf-8&pn=50",
#"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('.//a[@title]/text()').extract()
for i in sites:
print ('提示 这是title 提示 这是title 提示 这是title',i)
yield items
上面的代码出现了如下错误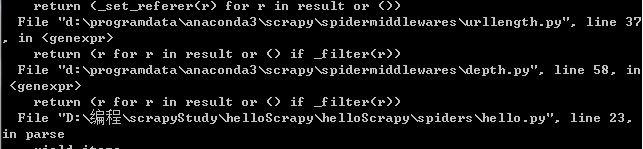
把
yield items
改为 yield sites
时,没有报错 但是 123.json文件是空的







