INNER PEACE M的博客python处理数组的时候,报错:IndexError: list assignment index out of range 有两种原因: 定义的数组边界过小,真的是出界了; 定义的空数组按照下标赋值就会报错; s = list() s[0] = 0 # IndexError: list ...
Robin_思源的博客在使用空数组赋值时遇到了:IndexError: list assignment index out of range ** 解决方法如下: 需要在赋值前先扩展空间,可以用那个较长的变量去扩展,如 write_table = [] write_table = [0]*len(key_col) write...
@...陈...@的博客for n in range(1,len(R)): if R[n] in R[:n]: R.remove(R[n]) print('去重后的R:'+str(R)) 代码运行报错“IndexError: listindex out of range”(如下图)的原因是: 执行R.remove()后,R一旦删除元素,其长度会...
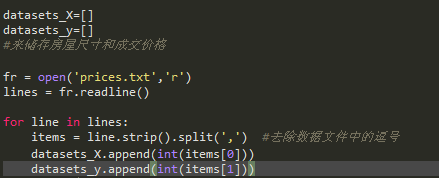图片说明](https://img-ask.csdn.net/upload/201709/17/1505650081_306728.png) 图片说明](https://img-ask.csdn.net/upload/201709/17/1505650042_786510.pn
图片说明](https://img-ask.csdn.net/upload/201709/17/1505650042_786510.pn
 分享
分享




