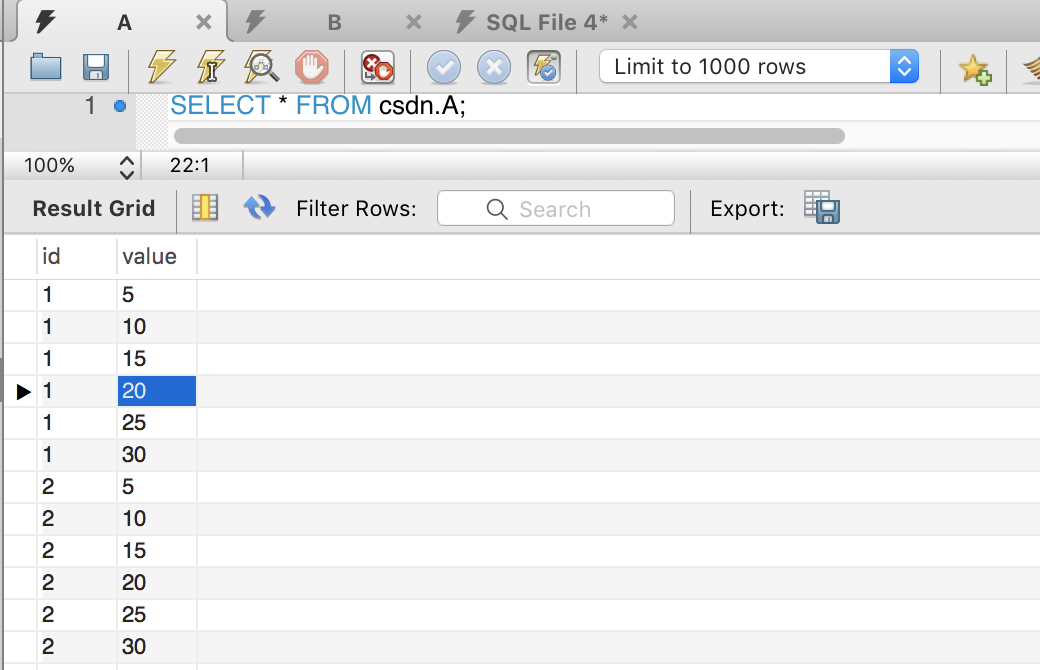
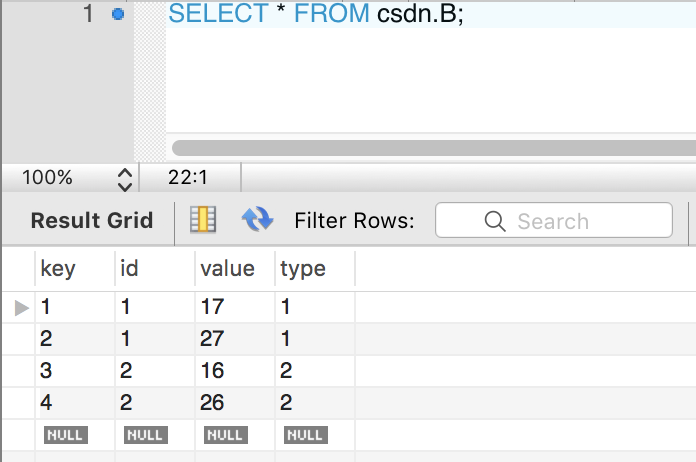
有两张表如图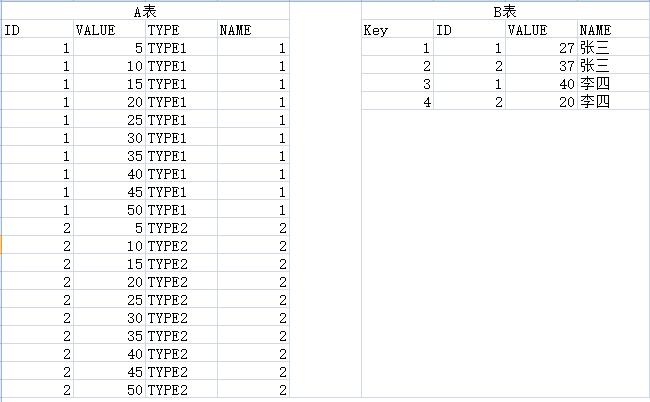
想根据B.Name in ('张三','李四') 来获取 8条数据
如图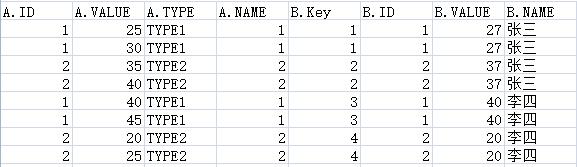
A表复合主键 ID+Vaule
B表主键Name
A.ID=B.ID
简单说来就是 取出B表同一个ID下 小于Value 的最大数据 和大于Value的最小数据
当B.Value处于 0或者max的时候只取出 一条(满足条件)即可
不限制 sql或者存储过程...
只需得到结果
这个问题我已经思考很久了, 并非一点sql 都不会 万望回答的朋友三思
---------------------------------------------------------分割线 以下内容为测试用建表sql以及数据
CREATE TABLE B(
[Name] nvarchar NOT NULL,
[ID] [int] NOT NULL,
[Value] [int] NOT NULL ,
[KEY] [int] NULL,
CONSTRAINT [PK_BAS_B] PRIMARY KEY CLUSTERED
(
[Name] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('张三' ,1 ,27 ,1)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('张三' ,2 ,37 ,2)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('李四' ,1 ,20 ,3)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('李四' ,2 ,40 ,4)
CREATE TABLE A(
[ID] [int] NOT NULL,
[Value] [int] NOT NULL ,
[TYPE] [int] NULL,
[NAME] nvarchar NULL,
CONSTRAINT [PK_BAS_A] PRIMARY KEY CLUSTERED
(
[ID] ASC,
[Value] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,5,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,10,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,15,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,20,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,25,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,30,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,35,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,40,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,45,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,50,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,5,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,10,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,15,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,20,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,25,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,30,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,35,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,40,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,45,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,50,2,'test')