python小白一枚,刚开始学爬虫,遇到一个动态网页爬取问题,请教各位大神。
需要爬取http://view.news.qq.com/original/intouchtoday/n4083.html
这篇新闻的评论内容,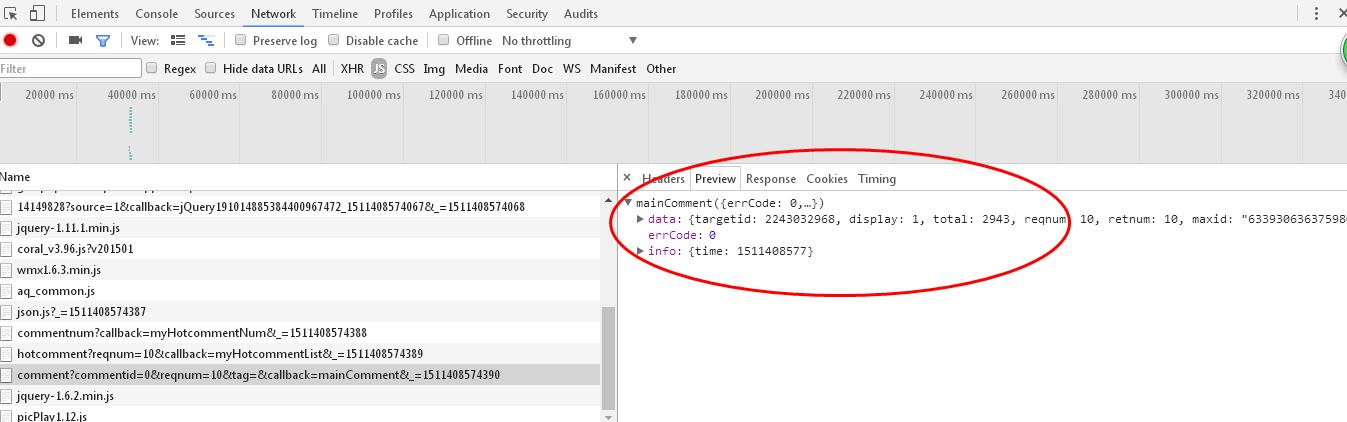
但是在找到了目标request url:
http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&ca,llback=mainComment&_=1511408574390
,不知道怎么提取里面的评论内容,且里面的内容类似于\u***这样的乱码
python爬虫爬取腾讯新闻评论

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 oyljerry 2017-11-23 06:09关注
oyljerry 2017-11-23 06:09关注需要先把内容的mainComment()去掉,它里面是一个json,然后就可以处理,\u是表示unicode的字符。
In [24]: sess = requests.Session() In [24]: sess.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Geck ...: o) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}) In [24]: res = sess.get("http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&callback=mainCommen ...: t&_=1511408574390") g = re.match("mainComment\\((.+)\\)", res.text) In [24]: out = json.loads(g.group(1)) In [23]: print(out["data"]["commentid"][0]["content"]) 方便面可以吃不放调料,自己煮,自己搭配本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2020-11-20 20:54weixin_39926040的博客 腾讯新闻的科技板块,至于为什么爬这个板块?我们要做新时代的科技少年???? ???? ???? 。闲话少叙,快上车。一、分析网页代码打开网页并进入调试模式,可以看的我们要爬取的内容都在这个 中。qqxw_01.png打开看看,...
- 2020-08-23 07:32前端技术的博客 python爬虫爬取腾讯新闻 话不多说,直接上代码! import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() #r.encoding = 'utf-...
- 2021-04-09 22:29变强的猴子的博客 爬取腾讯新闻首页的新闻内容 最近学习了爬虫,爬了一些内容,分享一下,方便大家。 import urllib.request import urllib.error import re,ssl #异常处理 try: #针对https ,需要单独处理 #import ssl #ssl._...
- 2023-09-18 13:26程序小武的博客 对爬取的数据进行可视化
- 2020-11-20 20:54weixin_39573981的博客 最近学了一段时间的Python,想写个爬虫,去网上找了找,然后参考了一下自己写了一个爬取给定页面的爬虫。Python的第三方库特别强大,提供了两个比较强大的库,一个requests, 另外一个BeautifulSoup,这两个库目前...
- 2024-04-15 19:04m0_60607245的博客 Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的...
- 2020-11-20 20:54weixin_39855796的博客 以打开腾讯新闻官网为例,我们在地址栏输入“http://news.qq.com/”,浏览器上呈现的是下图:Python学习交流群:1004391443,这里有资源共享,技术解答,还有小编从最基础的Python资料到项目实战的学...
- 2024-04-18 01:06m0_60635001的博客 这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。select = int(input(‘你要看第几集:...
- 2024-12-01 22:35萧鼎的博客 腾讯新闻网站包含丰富的新闻资源。爬取文章的标题和部分内容(200个字符)。点击“下一页”按钮后跳转到新页面并继续爬取。处理爬取内容中的特殊字符。将爬取到的内容保存到 CSV 文件中。本项目适合初学者学习 ...
- 2025-04-02 20:09Logan_h0的博客 (这里的m3u8文件我们通过txt的形式保存进本地,其实我们现在找到的m3u8就是视频切片存储的地址)这里up只简单举了一个例子(只能一次爬取一集),大家可以在此基础上再自行完善。2.在Network中找到m3u8文件(视频...
- 没有解决我的问题, 去提问
