
solr7.1.0配置分词器后查询时不分词,但在solr客户端analysis中可以分词成功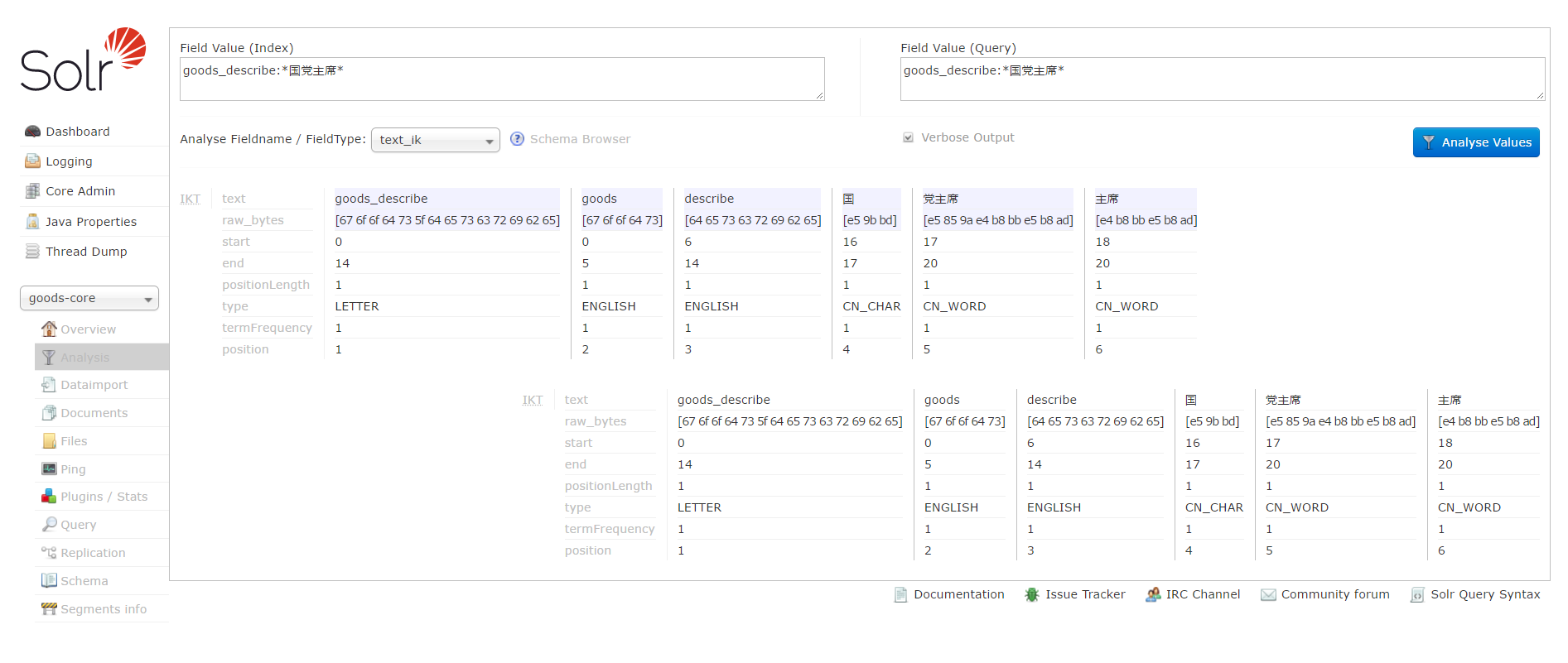
1、managed-schema中ik配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" isMaxWordLength="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" isMaxWordLength="true"/>
</analyzer>
2、使用了solr7.1.0自带的分词器也是查询时没分词。







